
[ 데이터 조회 및 라벨링 ]
머신러닝딥러닝용 데이터의 컬럼입니다.
['buy_dtls_nm', 'buy_pd_nm', 'user_id', 'user_gender', 'user_birth',
'user_address', 'user_family_counts', 'prod_prc', 'prod_company',
'prod_ctcd', 'buy_ymd', 'buy_day', 'buy_season', 'buy_hour',
'prc_level']
독립변수로는 회원 성별, 연령대, 거주지, 가구원수, 구매 요일, 구매 계절, 구매 시간
종속변수로는 제품 가격, 제조회사가 있습니다.
○ 구매 요일 컬럼 buy_day
from datetime import datetime
day_of_week = [int(i.strftime("%w")) for i in df["buy_ymd"]]
# (0은 일요일...6은 토요일)
df["buy_day"] = day_of_week▶ 주문 일자에서 요일을 구했습니다.
0은 일요일, 1은 월요일...6은 토요일 으로 숫자형으로 라벨링하였습니다.
○ 구매 계절 컬럼 buy_season
# 구매 계절 컬럼
month_list = [i.month for i in df["buy_ymd"]]
# 3 3 11 11 6 9 8
season = []
for i in month_list:
if i in [12,1,2]:
season.append(3)
elif i in [3,4,5]:
season.append(0)
elif i in [6,7,8]:
season.append(1)
else:
season.append(2)
df["buy_season"] = season▶ 봄이 0 여름이 2 ... 주문일자의 월을 기준으로 계절을 분류하여 숫자로 라벨링하였습니다.
○ 구매 시간 컬럼 buy_hour
# 구매 시간 컬럼
df["buy_hour"] = [i.hour for i in df["buy_ymd"]]○ 성별 컬럼 user_gender
gender = [0 if i == "M" else 1 for i in df["user_gender"]]
df["user_gender"] = gender○ 회원 거주지 컬럼 user_address
# 회원 거주지
addr = []
for i in df["user_address"] :
if "서울" in i:
addr.append(0)
elif "경기도" in i:
addr.append(1)
elif "인천" in i:
addr.append(2)
elif "부산" in i:
addr.append(3)
elif "충청북도" in i:
addr.append(4)
elif "대구" in i:
addr.append(5)
elif "충청남도" in i:
addr.append(6)
elif "강원도" in i:
addr.append(7)
elif "경상남도" in i:
addr.append(8)
elif "경상북도" in i:
addr.append(9)
elif "대전" in i:
addr.append(10)
elif "울산" in i:
addr.append(11)
elif "전라북도" in i:
addr.append(12)
elif "전라남도" in i:
addr.append(13)
elif "광주" in i:
addr.append(14)
else :
addr.append(15)
df["user_address"] = addr○ 가구원수 컬럼 user_family_counts
fc = [int(i[0]) for i in df["user_family_counts"]]
df["user_family_counts"] = fc
○ 제조회사 prod_company
data = data_all[data_all["prod_ctcd"] == "C001"]
company_dic = {}
# 값의 빈도수를 계산
value_counts = data["prod_company"].value_counts()
# 빈도수가 많은 순서대로 정렬
# sorted_values = value_counts.sort_values(ascending=False)
for n , i in enumerate(value_counts.index):
company_dic[i] = n
if n == 3 :
company_dic[i] = 2
elif n == 5 or n == 4:
company_dic[i] = 3
elif n > 5 and n < 8 :
company_dic[i] = 4
elif n >= 8:
company_dic[i] = 5
else:
company_dic[i] = n
data.loc[:, "prod_company"] = [ company_dic[i] for i in data["prod_company"]]▶ 카테고리 별로 나누어 회사중 가장 많은 구매내역이 있는 것을 기준으로 내림차순하여 회사명을 숫자형으로 변경하였습니다.
○ 가격대 컬럼 prc_level
prc_list = []
for i in data["prod_prc"]:
if i <1000000:
prc_list.append(0)
elif i >=1000000 and i<2000000 :
prc_list.append(1)
elif i >=2000000 and i<3000000 :
prc_list.append(2)
elif i >=3000000 and i<4000000 :
prc_list.append(3)
elif i >=4000000 and i<5000000 :
prc_list.append(4)
else:
prc_list.append(5)
# 데이터프레임 복사 후 .loc[]를 사용하여 명시적으로 값을 설정
data = data.copy()
data.loc[:,"prc_level"] = prc_list▶ 전기밥솥을 제외한 나머지는 100만원 단위 전기밥솥은 10만원 단위로 범주화 하였습니다.
[ 데이터 전처리 및 상관관계 검정 ]
모든 카테고리에 대해 가격과 제조회사 각각의 종속변수에 대한 훈련과 모델 생성 및 예측을 위해
각각 카테고리별로 독립변수와 종속변수사이의 상관관계를 확인했습니다
○ 상관관계 검정 전 X, y 로 독립변수와 종속변수를 나누는 함수
# 상관관계 검정은 출력하지 않는 함수
def cor_sep(df,ctcd, choice):
df_ctgr = df[df["prod_ctcd"] == ctcd].copy()
company_dic = {}
for n , i in enumerate(df_ctgr["prod_company"].unique()):
company_dic[i] = n
company = [ company_dic[i] for i in df_ctgr["prod_company"]]
df_ctgr["prod_company"] = company
df_ctgr_choice = df_ctgr[["user_gender","user_address","user_family_counts","buy_day","buy_season","buy_hour", choice]]
X = df_ctgr_choice.iloc[:,:-1]
y = df_ctgr_choice.iloc[:,-1]
return X,y
○ 상관관계 검정 함수
# ctcd : 카테고리 코드
# choice : 가격 prod_prc, 제조회사 prod_company 중 택
def cor(df,ctcd, choice):
df_ctgr = df[df["prod_ctcd"] == ctcd].copy()
company_dic = {}
for n , i in enumerate(df_ctgr["prod_company"].unique()):
company_dic[i] = n
company = [ company_dic[i] for i in df_ctgr["prod_company"]]
df_ctgr["prod_company"] = company
df_ctgr_choice = df_ctgr[["user_gender","user_address","user_family_counts","buy_day","buy_season","buy_hour", choice]]
X = df_ctgr_choice.iloc[:,:-1]
y = df_ctgr_choice.iloc[:,-1]
correlation_matrix = df_ctgr_choice.corr()
# 상관관계 히트맵
# plt.figure(figsize=(10,8))
# plt.title("상관관계 히트맵")
# sns.heatmap(correlation_matrix,annot=True,fmt='.3f',
# linewidths=.5,cmap="coolwarm",cbar = None)
cnt = 0
for column in X.columns:
corr,p_value = pearsonr(X[column],y)
print(f"{column} vs {choice} : {corr:.4f}/p-value = {p_value:.4f}")
if p_value < 0.5:
cnt+=1
print(f"{ctcd}, {choice} : 유의미한 특성개수{cnt}")
return X,y
○ 함수 호출하기
# 함수 호출하기
ctcd = ["C001","C002","C003","C004","C005"]
choice = ["prod_company","prc_level"]
for ct in ctcd:
for ch in choice:
print(f"--------{ct} / {ch}--------")
cor(df, ct, ch)--------C001 / prod_company--------
user_gender vs prod_company : 0.0033/p-value = 0.7769
user_address vs prod_company : 0.0110/p-value = 0.3495
user_family_counts vs prod_company : 0.0062/p-value = 0.5965
buy_day vs prod_company : -0.0056/p-value = 0.6334
buy_season vs prod_company : -0.0039/p-value = 0.7423
buy_hour vs prod_company : 0.0033/p-value = 0.7780
C001, prod_company : 유의미한 특성개수1
--------C001 / prc_level--------
user_gender vs prc_level : 0.0039/p-value = 0.7368
user_address vs prc_level : -0.0027/p-value = 0.8181
user_family_counts vs prc_level : 0.0056/p-value = 0.6324
buy_day vs prc_level : 0.0131/p-value = 0.2636
buy_season vs prc_level : -0.0107/p-value = 0.3624
buy_hour vs prc_level : -0.0022/p-value = 0.8482
C001, prc_level : 유의미한 특성개수2
--------C002 / prod_company--------
user_gender vs prod_company : 0.0076/p-value = 0.4931
user_address vs prod_company : 0.0040/p-value = 0.7179
user_family_counts vs prod_company : -0.0075/p-value = 0.4981
buy_day vs prod_company : 0.0049/p-value = 0.6571
buy_season vs prod_company : -0.0070/p-value = 0.5283
buy_hour vs prod_company : -0.0008/p-value = 0.9437
C002, prod_company : 유의미한 특성개수2
--------C002 / prc_level--------
user_gender vs prc_level : -0.0125/p-value = 0.2606
user_address vs prc_level : 0.0107/p-value = 0.3370
user_family_counts vs prc_level : 0.0131/p-value = 0.2388
buy_day vs prc_level : 0.0132/p-value = 0.2344
buy_season vs prc_level : 0.0027/p-value = 0.8109
buy_hour vs prc_level : -0.0057/p-value = 0.6116
C002, prc_level : 유의미한 특성개수4
--------C003 / prod_company--------
user_gender vs prod_company : -0.0280/p-value = 0.0056
user_address vs prod_company : 0.0151/p-value = 0.1345
user_family_counts vs prod_company : 0.0180/p-value = 0.0742
buy_day vs prod_company : -0.0077/p-value = 0.4480
buy_season vs prod_company : -0.0013/p-value = 0.8999
buy_hour vs prod_company : 0.0109/p-value = 0.2807
C003, prod_company : 유의미한 특성개수5
--------C003 / prc_level--------
user_gender vs prc_level : -0.0068/p-value = 0.5025
user_address vs prc_level : 0.0049/p-value = 0.6306
user_family_counts vs prc_level : 0.0030/p-value = 0.7659
buy_day vs prc_level : 0.0014/p-value = 0.8917
buy_season vs prc_level : 0.0047/p-value = 0.6390
buy_hour vs prc_level : -0.0130/p-value = 0.1991
C003, prc_level : 유의미한 특성개수1
--------C004 / prod_company--------
user_gender vs prod_company : -0.0138/p-value = 0.2316
user_address vs prod_company : -0.0104/p-value = 0.3688
user_family_counts vs prod_company : 0.0122/p-value = 0.2922
buy_day vs prod_company : 0.0026/p-value = 0.8206
buy_season vs prod_company : -0.0084/p-value = 0.4663
buy_hour vs prod_company : 0.0142/p-value = 0.2199
C004, prod_company : 유의미한 특성개수5
--------C004 / prc_level--------
user_gender vs prc_level : 0.0163/p-value = 0.1577
user_address vs prc_level : 0.0046/p-value = 0.6910
user_family_counts vs prc_level : 0.0072/p-value = 0.5331
buy_day vs prc_level : -0.0246/p-value = 0.0333
buy_season vs prc_level : 0.0205/p-value = 0.0766
buy_hour vs prc_level : -0.0109/p-value = 0.3450
C004, prc_level : 유의미한 특성개수4
--------C005 / prod_company--------
user_gender vs prod_company : 0.0103/p-value = 0.3761
user_address vs prod_company : -0.0012/p-value = 0.9202
user_family_counts vs prod_company : -0.0066/p-value = 0.5707
buy_day vs prod_company : -0.0081/p-value = 0.4837
buy_season vs prod_company : -0.0069/p-value = 0.5506
buy_hour vs prod_company : -0.0024/p-value = 0.8339
C005, prod_company : 유의미한 특성개수2
--------C005 / prc_level--------
user_gender vs prc_level : 0.0110/p-value = 0.3415
user_address vs prc_level : 0.0009/p-value = 0.9394
user_family_counts vs prc_level : 0.0070/p-value = 0.5471
buy_day vs prc_level : -0.0065/p-value = 0.5744
buy_season vs prc_level : -0.0273/p-value = 0.0187
buy_hour vs prc_level : 0.0047/p-value = 0.6833
C005, prc_level : 유의미한 특성개수2
▶ 전체적으로 유의미한 특성개수가 적지만 유의미한 특성들이 보이는 것으로 판단하고 진행
독립변수가 범주형 데이터이기 때문에(라벨인코딩을 통해) 정규화가 필요하지 않음
[ 훈련 : 검증 : 테스트 6 : 2 : 2 로 분리 ]
def split(X,y):
X_train , X_temp , y_train , y_temp = train_test_split(X,y,test_size=0.4,random_state=42)
X_val, X_test , y_val,y_test = train_test_split(X_temp,y_temp,test_size=0.5,random_state=42)
print(X_train.shape,y_train.shape)
print(X_val.shape,y_val.shape)
print(X_test.shape,y_test.shape)
return X_train,X_val,X_test,y_train,y_val,y_test
[ 분류 모델 생성 및 하이퍼파라메터 튜닝 ]
○ 하이퍼파라메터 튜닝 함수
# 하이퍼파라메터 튜닝
def get_best_model(X_train, X_val, y_train, y_val):
# 모델 생성하기
rf_model = RandomForestClassifier()
et_model = ExtraTreesClassifier()
gb_model = GradientBoostingClassifier()
hg_model = HistGradientBoostingClassifier()
xgb_model = XGBClassifier()
mpl_model = MLPClassifier(random_state=42)
# 모델 리스트 생성
models = [rf_model,et_model,gb_model,hg_model,xgb_model,mpl_model]
# 하이퍼파라메터 튜닝
df= pd.DataFrame()
scoring = ["accuracy"]
refit = "accuracy"
for model in models:
modelName = model.__class__.__name__
gridParams = {}
print(f"------------[{modelName}]------------")
if modelName in ['RandomForestClassifier','ExtraTreesClassifier','GradientBoostingClassifier']:
gridParams["max_depth"] =[3,10]
gridParams["n_estimators"] = [20,40,70]
gridParams["min_samples_split"] = [2,5,10]
gridParams["min_samples_leaf"] = [1,5,10]
elif modelName == "HistGradientBoostingClassifier":
gridParams["max_depth"] = [3 , 10]
gridParams["max_iter"] = [50,100,500]
gridParams["min_samples_leaf"] = [1,5,10]
elif modelName == "XGBClassifier":
gridParams["max_depth"] = [ 3 , 10]
gridParams["n_estimators"] = [20,40,70]
gridParams["min_child_weight"] = [1,5,10]
else:
gridParams["hidden_layer_sizes" ] = [(10,),(100)]
gridParams["alpha"] = [0.0001,0.001,0.01]
gridParams["max_iter"] = [1000]
grid_search_model = GridSearchCV(model, gridParams,scoring=scoring,refit=refit,cv=5,n_jobs=-1)
grid_search_model.fit(X_train,y_train)
best_model = grid_search_model.best_estimator_
train_pred = best_model.predict(X_train)
val_pred = best_model.predict(X_val)
train_acc = accuracy_score(y_train, train_pred)
val_acc = accuracy_score(y_val, val_pred)
precision = precision_score(y_val, val_pred,average="micro")
recall = recall_score(y_val, val_pred,average="micro")
f1 = f1_score(y_val, val_pred,average="micro")
print(precision,recall,f1)
cm = confusion_matrix(y_val, val_pred)
print("최적의 파라메터들 : ",grid_search_model.best_params_)
print("성능평가결과[정확도] : ", grid_search_model.best_score_)
print("최적의 모델 :", grid_search_model.best_estimator_)
df_eval = pd.DataFrame([[modelName,train_acc,val_acc,precision,recall,f1,cm]],columns=["모델이름","훈련정확도","검증정확도","정밀도","재현율","f1-score","혼동행렬"])
df = pd.concat([df,df_eval],ignore_index=True)
print()
return df
○ 함수 호출하기
ctcd = ["C001","C002","C003","C004","C005"]
choice = ["prod_company","prc_level"]
df_bestmodel = pd.DataFrame()
for ch in choice:
print(f"----------- {ch} -------------")
for ct in ctcd:
print(f"--------{ct} / {ch}--------")
# 상관관계 검정 제외
X,y = cor_sep(df,ct,ch)
X_train,X_val, X_test, y_train, y_val, y_test = split(X,y)
df_1= get_best_model(X_train, X_val, y_train, y_val)
df_bestmodel = pd.concat([df_bestmodel,df_1],ignore_index=True)▶ 데이터셋에서 어떤 클래스의 샘플 수가 교차검증의 각 폴드에서 너무 적어서 경고가 발생함
Stratified K-Fold를 통해 해결
[ Stratified K-Fold 사용 모델 ]
○ Stratified K-Fold 사용 최적 모델 선정 위한 성능 평가 지표 출력 함수
다층 퍼셉트론의 경우에는 최대 반복횟수에 도달하였지만 최적화가 아직 수렴하지 않았음을 나타내는 오류가 발생하였습니다. 최적의 가중치를 못찾는 것, 따라서 제외하고 분류 앙상블 모델 다섯가지만 두고 진행하였습니다
# shuffle=True : 모든 폴드에서 클래스의 분포가 균등하게 유지되도록 도와줌
from sklearn.model_selection import StratifiedKFold
def skfold_split(X,y,n_splits):
# # 클래스 분포 확인
# class_distribution = y.value_counts()
# # 가장 샘플 수가 적은 클래스 식별
# min_samples_class = class_distribution.min()
# # n_splits 조정
# n_splits = min(n_splits, min_samples_class)
skf = StratifiedKFold(n_splits=n_splits,shuffle=True,random_state=42)
df_total = pd.DataFrame()
df_tot = pd.DataFrame()
rf_model = RandomForestClassifier()
et_model = ExtraTreesClassifier()
gb_model = GradientBoostingClassifier()
hg_model = HistGradientBoostingClassifier()
xgb_model = XGBClassifier()
# mpl_model = MLPClassifier(random_state=42)
# 모델 리스트 생성
models = [rf_model,et_model,gb_model,hg_model,xgb_model]
for model in models:
modelName = model.__class__.__name__
for train_index, test_index in skf.split(X,y):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model.fit(X_train,y_train)
train_pred = model.predict(X_train)
y_pred = model.predict(X_test)
# # 예측값 중에서 훈련 데이터에 없는 종속변수 확인
# unseen_classes = set(y_pred) - set(train_pred)
# # 예측값을 새로운 클래스로 재라벨링
# for unseen_class in unseen_classes:
# y_pred = np.where(y_pred == unseen_class, 50, y_pred)
train_acc = accuracy_score(y_train,train_pred)
test_acc = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred,average="micro")
recall = recall_score(y_test, y_pred,average="micro")
f1 = f1_score(y_test,y_pred,average="micro")
cm = confusion_matrix(y_test, y_pred)
df_eval = pd.DataFrame([[modelName,train_acc,test_acc,precision,recall,f1,cm]],columns=["모델이름","훈련정확도","테스트정확도","정밀도","재현율","f1-score","혼동행렬"])
print(modelName,train_acc,test_acc,precision,recall,f1)
print()
df_total = pd.concat([df_total,df_eval],ignore_index=True)
df_tot = pd.concat([df_tot,df_total],ignore_index=True)
return df_tot
○ 종속변수 제조회사에 대한 최적의 모델 선정
# 제조회사만
ctcd = ["C001","C002","C003","C004","C005"]
result_list = []
for ct in ctcd:
print(f"----------- {ct} -------------")
X,y = cor_sep(df,ct,"prod_company")
# X_train,X_val,X_test,y_train,y_val,y_test = split(X,y)
df_t = skfold_split(X,y,5)
result_list.append(df_t)
df_total = pd.concat(result_list,ignore_index=True)
이때 n_splits를 3으로 뒀을때와 5로 뒀을때를 각각 구해서 데이터 프레임에 저장하였습니다.
df1 = pd.read_csv("전체카테고리_제조사_skfold_split_n_split3.csv")
df2 = pd.read_csv("전체카테고리_제조사_skfold_split_n_split5.csv")
print(df1[df1["훈련정확도"] == df1["훈련정확도"].max()].iloc[:,:4])
print(df2[df2["훈련정확도"] == df2["훈련정확도"].max()].iloc[:,:4])
훈련정확도가 높은 행을 출력해보니 결과가 다음과 같았습니다.
Unnamed: 0 모델이름 훈련정확도 테스트정확도
152 152 RandomForestClassifier 0.89103 0.481879
157 157 RandomForestClassifier 0.89103 0.481879
162 162 ExtraTreesClassifier 0.89103 0.475753
167 167 RandomForestClassifier 0.89103 0.481879
172 172 ExtraTreesClassifier 0.89103 0.475753
182 182 RandomForestClassifier 0.89103 0.481879
187 187 ExtraTreesClassifier 0.89103 0.475753
202 202 RandomForestClassifier 0.89103 0.481879
207 207 ExtraTreesClassifier 0.89103 0.475753
Unnamed: 0 모델이름 훈련정확도 테스트정확도
152 152 RandomForestClassifier 0.89103 0.473711
157 157 RandomForestClassifier 0.89103 0.473711
162 162 ExtraTreesClassifier 0.89103 0.475242
167 167 RandomForestClassifier 0.89103 0.473711
172 172 ExtraTreesClassifier 0.89103 0.475242
182 182 RandomForestClassifier 0.89103 0.473711
187 187 ExtraTreesClassifier 0.89103 0.475242
202 202 RandomForestClassifier 0.89103 0.473711
207 207 ExtraTreesClassifier 0.89103 0.475242
▶ 훈련정확도가 0.89103으로 동일하지만 n_split 을 3으로 둔 경우가 테스트 정확도가 0.481879로 0.01정도 더 높게 나타남
특히 RandomForestClassifier가 더 높게 나타남
그러나 훈련정확도와 테스트 정확도의 차이가 크므로 과대적합임
따라서 특성공학을 사용하기로 결정함
[ 특성공학 - 다항 특성 추가 ]
from sklearn.preprocessing import PolynomialFeatures
def poly_skf_split(X, y, n_splits):
skf = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=42)
df_total = pd.DataFrame()
df_tot = pd.DataFrame()
rf_model = RandomForestClassifier()
et_model = ExtraTreesClassifier()
gb_model = GradientBoostingClassifier()
hg_model = HistGradientBoostingClassifier()
xgb_model = XGBClassifier()
# mpl_model = MLPClassifier(random_state=42)
# 다항 특성 추가
degree = 2 # 2차 다항식을 적용
poly_features = PolynomialFeatures(degree=degree, include_bias=False)
X_poly = poly_features.fit_transform(X)
# 모델 리스트 생성
models = [rf_model, et_model, gb_model, hg_model, xgb_model]
for model in models:
modelName = model.__class__.__name__
for train_index, test_index in skf.split(X_poly, y):
X_train, X_test = X_poly[train_index], X_poly[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model.fit(X_train, y_train)
train_pred = model.predict(X_train)
y_pred = model.predict(X_test)
train_acc = accuracy_score(y_train, train_pred)
test_acc = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average="micro")
recall = recall_score(y_test, y_pred, average="micro")
f1 = f1_score(y_test, y_pred, average="micro")
cm = confusion_matrix(y_test, y_pred)
df_eval = pd.DataFrame([[modelName, train_acc, test_acc, precision, recall, f1, cm]], columns=["모델이름", "훈련정확도", "테스트정확도", "정밀도", "재현율", "f1-score", "혼동행렬"])
print(modelName, train_acc, test_acc, precision, recall, f1)
print()
df_total = pd.concat([df_total, df_eval], ignore_index=True)
df_tot = pd.concat([df_tot, df_total], ignore_index=True)
return df_tot
ctcd = ["C001","C002","C003","C004","C005"]
result_list = []
for ct in ctcd:
print(f"----------- {ct} -------------")
X,y = cor_sep(df,ct,"prod_company")
df_t = poly_skf_split(X,y,3)
result_list.append(df_t)
df_total = pd.concat(result_list,ignore_index=True)
----------- C001 -------------
RandomForestClassifier 0.9021065675340768 0.372573316811235 0.372573316811235 0.372573316811235 0.372573316811235
RandomForestClassifier 0.9056175134242048 0.3610078479966956 0.3610078479966956 0.3610078479966956 0.3610078479966956
RandomForestClassifier 0.9043783560512185 0.36926889714993805 0.36926889714993805 0.36926889714993805 0.36926889714993805
ExtraTreesClassifier 0.9021065675340768 0.35811648079306074 0.35811648079306074 0.35811648079306074 0.35811648079306074
ExtraTreesClassifier 0.9056175134242048 0.3506815365551425 0.3506815365551425 0.3506815365551425 0.3506815365551425
ExtraTreesClassifier 0.9043783560512185 0.36018174308137135 0.36018174308137135 0.36018174308137135 0.3601817430813713
GradientBoostingClassifier 0.5510119785212721 0.41924824452705495 0.41924824452705495 0.41924824452705495 0.41924824452705495
GradientBoostingClassifier 0.5462618752581578 0.4250309789343247 0.4250309789343247 0.4250309789343247 0.4250309789343247
GradientBoostingClassifier 0.5503923998347791 0.40850888062783974 0.40850888062783974 0.40850888062783974 0.4085088806278397
HistGradientBoostingClassifier 0.8228004956629492 0.36472532011565467 0.36472532011565467 0.36472532011565467 0.36472532011565467
HistGradientBoostingClassifier 0.8199091284593143 0.36224700536968196 0.36224700536968196 0.36224700536968196 0.36224700536968196
HistGradientBoostingClassifier 0.8174308137133416 0.36761668731928954 0.36761668731928954 0.36761668731928954 0.36761668731928954
XGBClassifier 0.8572903758777365 0.3593556381660471 0.3593556381660471 0.3593556381660471 0.35935563816604704
XGBClassifier 0.862453531598513 0.35811648079306074 0.35811648079306074 0.35811648079306074 0.35811648079306074
XGBClassifier 0.8593556381660471 0.37587773647253203 0.37587773647253203 0.37587773647253203 0.375877736472532
...
▶다항 특성을 추가하였음에도 여전히 검증정확도가 높아지지 않고 큰 차이를 보였습니다.
여러 방법을 시도해봤지만 가상데이터가 너무 고르게 분포되어있어 문제가 발생한다고 판단하였고 가상데이터의 종속변수의 범주를 간소화하는 작업을 진행하였습니다.
다음은 간소화 뒤의 과정입니다
[ 전처리 및 상관관계 검정 ]
○ 독립변수와 종속변수로 분리하는 함수
def sep(df,choice):
df_choice = df[["user_gender","user_address","user_age","user_family_counts","buy_day","buy_season","buy_hour" ,choice]]
X = df_choice.iloc[:,:-1]
y = df_choice.iloc[:,-1]
return X,y
○ 상관관계함수
def cor(df):
correlation_matrix = df.corr()
return correlation_matrix
○ 상관관계 히트맵 시각화 함수
def cor_plot(correlation_matrix):
plt.figure(figsize=(10,8))
plt.title("상관관계 히트맵")
sns.heatmap(correlation_matrix,annot=True,fmt='.3f',
linewidths=.5,cmap="Blues",cbar = None)
plt.show()
○ 피어슨 상관관계 검정 함수
def cor_pearson(ctcd, choice,X,y):
cnt = 0
for column in X.columns:
corr,p_value = pearsonr(X[column],y)
print(f"{column} vs {choice} : {corr:.4f}/p-value = {p_value:.4f}")
if p_value < 0.5:
cnt+=1
print(f"{ctcd}, {choice} : 유의미한 특성개수{cnt}")
○ 상관관계 히트맵
에어컨 - 종속변수 prc_level 의 히트맵입니다

○ p-value 검정
df_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
for choice in choice_list:
print(f"-------------{choice}-------------")
n = 0
for df in df_list:
X,y = sep(df,choice)
cor_pearson(ctcd[n],choice,X,y)
n+=1-------------prc_level-------------
user_gender vs prc_level : -0.2311/p-value = 0.0000
user_address vs prc_level : -0.0819/p-value = 0.0000
user_age vs prc_level : -0.2245/p-value = 0.0000
user_family_counts vs prc_level : 0.4426/p-value = 0.0000
buy_day vs prc_level : 0.3632/p-value = 0.0000
buy_season vs prc_level : -0.1099/p-value = 0.0000
buy_hour vs prc_level : 0.2979/p-value = 0.0000
냉장고, prc_level : 유의미한 특성개수7
user_gender vs prc_level : -0.2088/p-value = 0.0000
user_address vs prc_level : 0.0516/p-value = 0.0000
user_age vs prc_level : -0.2572/p-value = 0.0000
user_family_counts vs prc_level : 0.5472/p-value = 0.0000
buy_day vs prc_level : 0.2585/p-value = 0.0000
buy_season vs prc_level : -0.0263/p-value = 0.0183
buy_hour vs prc_level : 0.2565/p-value = 0.0000
tv, prc_level : 유의미한 특성개수7
user_gender vs prc_level : -0.2689/p-value = 0.0000
user_address vs prc_level : -0.1187/p-value = 0.0000
user_age vs prc_level : -0.2772/p-value = 0.0000
user_family_counts vs prc_level : 0.5959/p-value = 0.0000
buy_day vs prc_level : 0.3836/p-value = 0.0000
buy_season vs prc_level : -0.1385/p-value = 0.0000
buy_hour vs prc_level : 0.2811/p-value = 0.0000
세탁기, prc_level : 유의미한 특성개수7
user_gender vs prc_level : -0.1984/p-value = 0.0000
user_address vs prc_level : -0.1005/p-value = 0.0000
user_age vs prc_level : -0.1939/p-value = 0.0000
user_family_counts vs prc_level : 0.5443/p-value = 0.0000
buy_day vs prc_level : 0.3318/p-value = 0.0000
buy_season vs prc_level : -0.1090/p-value = 0.0000
buy_hour vs prc_level : 0.2871/p-value = 0.0000
에어컨, prc_level : 유의미한 특성개수7
user_gender vs prc_level : -0.2179/p-value = 0.0000
user_address vs prc_level : -0.1308/p-value = 0.0000
user_age vs prc_level : -0.2189/p-value = 0.0000
user_family_counts vs prc_level : 0.4949/p-value = 0.0000
buy_day vs prc_level : 0.3238/p-value = 0.0000
buy_season vs prc_level : -0.1499/p-value = 0.0000
buy_hour vs prc_level : 0.2896/p-value = 0.0000
전기밥솥, prc_level : 유의미한 특성개수7
-------------prod_company-------------
user_gender vs prod_company : 0.1383/p-value = 0.0000
user_address vs prod_company : 0.2691/p-value = 0.0000
user_age vs prod_company : 0.0340/p-value = 0.0037
user_family_counts vs prod_company : -0.3019/p-value = 0.0000
buy_day vs prod_company : -0.2268/p-value = 0.0000
buy_season vs prod_company : 0.2820/p-value = 0.0000
buy_hour vs prod_company : -0.1500/p-value = 0.0000
냉장고, prod_company : 유의미한 특성개수7
user_gender vs prod_company : 0.1248/p-value = 0.0000
user_address vs prod_company : 0.0535/p-value = 0.0000
user_age vs prod_company : -0.0065/p-value = 0.5582
user_family_counts vs prod_company : -0.3515/p-value = 0.0000
buy_day vs prod_company : -0.2007/p-value = 0.0000
buy_season vs prod_company : 0.1212/p-value = 0.0000
buy_hour vs prod_company : -0.1467/p-value = 0.0000
tv, prod_company : 유의미한 특성개수6
user_gender vs prod_company : 0.2142/p-value = 0.0000
user_address vs prod_company : 0.2727/p-value = 0.0000
user_age vs prod_company : 0.0782/p-value = 0.0000
user_family_counts vs prod_company : -0.1771/p-value = 0.0000
buy_day vs prod_company : -0.2273/p-value = 0.0000
buy_season vs prod_company : 0.2537/p-value = 0.0000
buy_hour vs prod_company : -0.0833/p-value = 0.0000
세탁기, prod_company : 유의미한 특성개수7
user_gender vs prod_company : 0.0741/p-value = 0.0000
user_address vs prod_company : 0.4231/p-value = 0.0000
user_age vs prod_company : -0.0575/p-value = 0.0000
user_family_counts vs prod_company : -0.1878/p-value = 0.0000
buy_day vs prod_company : -0.2057/p-value = 0.0000
buy_season vs prod_company : 0.3987/p-value = 0.0000
buy_hour vs prod_company : -0.1191/p-value = 0.0000
에어컨, prod_company : 유의미한 특성개수7
user_gender vs prod_company : 0.1723/p-value = 0.0000
user_address vs prod_company : 0.2356/p-value = 0.0000
user_age vs prod_company : 0.0419/p-value = 0.0003
user_family_counts vs prod_company : -0.3306/p-value = 0.0000
buy_day vs prod_company : -0.2286/p-value = 0.0000
buy_season vs prod_company : 0.2062/p-value = 0.0000
buy_hour vs prod_company : -0.2367/p-value = 0.0000
전기밥솥, prod_company : 유의미한 특성개수7
○ 훈련 검증 테스트 데이터 분리 함수
def split(X,y):
X_train , X_temp , y_train , y_temp = train_test_split(X,y,test_size=0.4,random_state=42)
X_val, X_test , y_val,y_test = train_test_split(X_temp,y_temp,test_size=0.5,random_state=42)
return X_train,X_val,X_test,y_train,y_val,y_test
[ 머신러닝 분류 앙상블 모델 기본값으로 생성 및 성능 평가 ]
○ 모델 생성 및 성능 평가 지표 저장 함수
def model_default(X_train,X_val,y_train,y_val):
df_tot = pd.DataFrame()
rf_model = RandomForestClassifier()
et_model = ExtraTreesClassifier()
gb_model = GradientBoostingClassifier()
hg_model = HistGradientBoostingClassifier()
xgb_model = XGBClassifier()
# mpl_model = MLPClassifier(random_state=42)
scoring = ["accuracy"]
refit = "accuracy"
# 모델 리스트 생성
models = [rf_model, et_model, gb_model, hg_model, xgb_model]
for model in models:
modelName = model.__class__.__name__
model.fit(X_train,y_train)
train_pred = model.predict(X_train)
val_pred = model.predict(X_val)
train_acc = accuracy_score(y_train, train_pred)
val_acc = accuracy_score(y_val, val_pred)
precision = precision_score(y_val, val_pred,average="micro")
recall = recall_score(y_val, val_pred,average="micro")
f1 = f1_score(y_val, val_pred,average="micro")
cm = confusion_matrix(y_val, val_pred)
df_eval = pd.DataFrame([[modelName,train_acc,val_acc,precision,recall,f1,cm]],columns=["모델이름","훈련정확도","검증정확도","정밀도","재현율","f1-score","혼동행렬"])
df_tot = pd.concat([df_tot,df_eval],ignore_index=True)
print()
return df_tot
○ 함수 호출
df_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
df_all = pd.DataFrame()
df_total = pd.DataFrame()
for choice in choice_list:
print(f"-------------{choice}-------------")
n=0
for df in df_list:
print(f"----------{ctcd[n]}-----------")
X,y = sep(df,choice)
X_train,X_val,X_test,y_train,y_val,y_test = split(X,y)
df_tot = model_default(X_train,X_val,y_train,y_val)
df_tot["ctgr"] = ctcd[n]
n+=1
df_total = pd.concat([df_total,df_tot],ignore_index=True)
df_all = pd.concat([df_all,df_total],ignore_index=True)
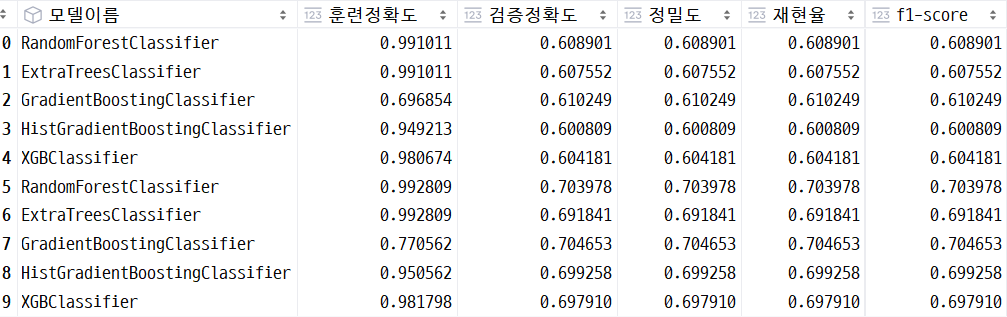
○ 성능 지표 확인
훈련 정확도가 가장 큰 모델 찾기
df_all[df_all["훈련정확도"] == df_all["훈련정확도"].max()]
훈련 정확도가 가장 큰 RandomForestClassifier와 ExtraTreesClassifier의 경우 검증정확도와의 차이가 너무 컸습니다.
따라서 그 차이가 작은 모델을 찾는 것이 중요하다고 생각이 들었습니다.
훈련정확도와 검증정확도의 차이가 가장 작은 모델 찾기
df_all[(df_all["훈련정확도"] - df_all["검증정확도"]) == (df_all["훈련정확도"] - df_all["검증정확도"]).min()]
GradientBoostingClassifier가 훈련정확도와 검증정확도의 차이가 작으므로 가장 일반화된 모델이라고 판단할 수 있습니다.
그러나 훈련정확도가 0.77 정도로 다소 아쉬워서 세 모델을 기준으로 하이퍼파라메터 튜닝을 한 후에 다시 비교해야되겠다는 판단을 하였습니다.
[ 하이퍼파라메터 튜닝 ]
○ 세가지 모델에 대한 하이퍼파라메터 튜닝 함수
# 하이퍼파라메터 튜닝
def get_best_model(X_train, X_val, y_train, y_val):
# 모델 생성하기
rf_model = RandomForestClassifier()
et_model = ExtraTreesClassifier()
gb_model = GradientBoostingClassifier()
# 모델 리스트 생성
models = [rf_model,et_model,gb_model]
# 하이퍼파라메터 튜닝
df= pd.DataFrame()
scoring = ["accuracy"]
refit = "accuracy"
for model in models:
modelName = model.__class__.__name__
gridParams = {}
print(f"------------[{modelName}]------------")
gridParams["max_depth"] =[3,10]
gridParams["n_estimators"] = [20,40,70]
gridParams["min_samples_split"] = [2,5,10]
gridParams["min_samples_leaf"] = [1,5,10]
grid_search_model = GridSearchCV(model, gridParams,scoring=scoring,refit=refit,cv=5,n_jobs=-1)
grid_search_model.fit(X_train,y_train)
best_model = grid_search_model.best_estimator_
train_pred = best_model.predict(X_train)
val_pred = best_model.predict(X_val)
train_acc = accuracy_score(y_train, train_pred)
val_acc = accuracy_score(y_val, val_pred)
precision = precision_score(y_val, val_pred,average="micro")
recall = recall_score(y_val, val_pred,average="micro")
f1 = f1_score(y_val, val_pred,average="micro")
print(val_acc,precision,recall,f1)
cm = confusion_matrix(y_val, val_pred)
print("최적의 파라메터들 : ",grid_search_model.best_params_)
print("성능평가결과[정확도] : ", grid_search_model.best_score_)
print("최적의 모델 :", grid_search_model.best_estimator_)
df_eval = pd.DataFrame([[modelName,train_acc,val_acc,precision,recall,f1,cm]],columns=["모델이름","훈련정확도","검증정확도","정밀도","재현율","f1-score","혼동행렬"])
df = pd.concat([df,df_eval],ignore_index=True)
print()
return df▶ 하이퍼파라메터 튜닝 설명
n_estimators: 부스팅 반복 횟수로, 트리의 개수입니다. 일반적으로 높은 값이 더 좋은 성능을 나타낼 수 있지만, 과적합을 일으킬 수도 있습니다.
learning_rate: 각 트리의 기여도를 줄이는 역할을 하는 학습률입니다. 작은 값이 더 안정적인 모델을 만들 수 있지만, 너무 작으면 학습이 더 오래 걸릴 수 있습니다.
max_depth: 각 트리의 최대 깊이로, 과적합을 조절하는데 사용됩니다.
min_samples_split: 내부 노드를 분할하기 위한 최소 샘플 수입니다. 작은 값은 더복잡한 모델을 만들 수 있습니다.
min_samples_leaf: 말단 노드의 최소 샘플 수로, 과적합을 방지하는 역할을 합니다.
○ 함수 호출
df_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
df_best_all = pd.DataFrame()
df_total = pd.DataFrame()
for choice in choice_list:
print(f"-------------{choice}-------------")
n=0
for df in df_list:
print(f"----------{ctcd[n]}-----------")
X,y = sep(df,choice)
X_train,X_val,X_test,y_train,y_val,y_test = split(X,y)
df_tot = get_best_model(X_train,X_val,y_train,y_val)
n+=1
df_total = pd.concat([df_total,df_tot],ignore_index=True)
df_best_all = pd.concat([df_best_all,df_total],ignore_index=True) 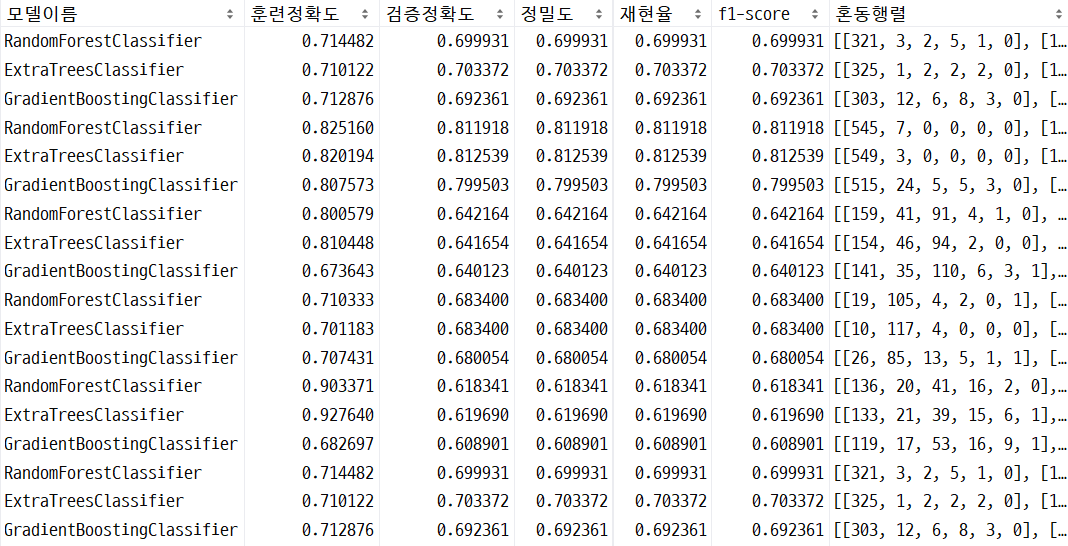
위와 같이 가장 큰 훈련정확도를 보이는 모델과 가장 적은 훈련정확도와 검증정확도의 차이를 보이는 모델을 출력하였습니다.
가장 높은 훈련정확도를 보이는 모델 ExtraTreesClassifier
튜닝 후에 훈련 정확도와 검증정확도의 차이가 다소 감소하였으나 훈련정확도도 감소하였습니다.

가장 작은 훈련정확도와 검증정확도의 차이를 보이는 모델 GradientBoostingClassifier
훈련정확도가 0.005정도 높아진 것을 확인할 수 있습니다.

따라서 일반화 되어있는 GradientBoostingClassifirer로 결정하였습니다.
[ GridSearchCV로 확인 ]
GradientBoosting 모델에 대해 GridSearchCV로 최적의 파라메터와 최적의 모델을 확인해봤습니다.
# GridSearchCV로 확인하기
# 사용 모델은 Gradient
def get_gbmodel(X_train, X_val, y_train, y_val):
# 모델 생성하기
gb_model = GradientBoostingClassifier()
# 하이퍼파라메터 튜닝
df= pd.DataFrame()
scoring = ["accuracy"]
refit = "accuracy"
modelName = gb_model.__class__.__name__
gridParams = {}
gridParams["max_depth"] =[3,4,5]
gridParams["n_estimators"] = [50,100,150]
gridParams["min_samples_split"] = [2,5,10]
gridParams["min_samples_leaf"] = [1,2,4]
gridParams["learning_rate"] = [0.01, 0.1, 0.2]
skf = StratifiedKFold(n_splits=3,shuffle=True,random_state=42)
grid_search_model = GridSearchCV(gb_model, gridParams,scoring=scoring,refit=refit,cv=skf,n_jobs=-1)
grid_search_model.fit(X_train,y_train)
best_model = grid_search_model.best_estimator_
train_pred = best_model.predict(X_train)
val_pred = best_model.predict(X_val)
test_pred = best_model.predict(X_test)
train_acc = accuracy_score(y_train, train_pred)
val_acc = accuracy_score(y_val, val_pred)
test_acc = accuracy_score(y_test, test_pred)
precision = precision_score(y_val, val_pred,average="micro")
recall = recall_score(y_val, val_pred,average="micro")
f1 = f1_score(y_val, val_pred,average="micro")
print(precision,recall,f1)
cm = confusion_matrix(y_val, val_pred)
print("최적의 파라메터들 : ",grid_search_model.best_params_)
print("성능평가결과[정확도] : ", grid_search_model.best_score_)
print("최적의 모델 :", grid_search_model.best_estimator_)
df_eval = pd.DataFrame([[modelName,train_acc,val_acc,test_acc,precision,recall,f1,cm]],columns=["모델이름","훈련정확도","검증정확도","테스트정확도","정밀도","재현율","f1-score","혼동행렬"])
df = pd.concat([df,df_eval],ignore_index=True)
print()
return dfdf_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
df_best_all = pd.DataFrame()
df_total = pd.DataFrame()
for choice in choice_list:
print(f"-------------{choice}-------------")
n=0
for df in df_list:
print(f"----------{ctcd[n]}-----------")
X,y = sep(df,choice)
X_train,X_val,X_test,y_train,y_val,y_test = split(X,y)
df_tot = get_gbmodel(X_train,X_val,y_train,y_val)
n+=1
df_total = pd.concat([df_total,df_tot],ignore_index=True)
df_best_all = pd.concat([df_best_all,df_total],ignore_index=True) -------------prc_level-------------
----------냉장고-----------
0.6827253957329663 0.6827253957329663 0.6827253957329663
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 50}
성능평가결과[정확도] : 0.6942866062868566
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=5, min_samples_leaf=2,
min_samples_split=10, n_estimators=50)
----------tv-----------
0.8050900062073246 0.8050900062073246 0.8050900062073246
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 100}
성능평가결과[정확도] : 0.7906062487068074
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=5, min_samples_leaf=2,
min_samples_split=10)
----------세탁기-----------
0.635017866258295 0.635017866258295 0.635017866258295
최적의 파라메터들 : {'learning_rate': 0.2, 'max_depth': 4, 'min_samples_leaf': 4, 'min_samples_split': 2, 'n_estimators': 50}
성능평가결과[정확도] : 0.633486472690148
최적의 모델 : GradientBoostingClassifier(learning_rate=0.2, max_depth=4, min_samples_leaf=4,
n_estimators=50)
----------에어컨-----------
0.6720214190093708 0.6720214190093708 0.6720214190093708
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 4, 'min_samples_leaf': 4, 'min_samples_split': 2, 'n_estimators': 100}
성능평가결과[정확도] : 0.6663688317308827
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=4, min_samples_leaf=4)
----------전기밥솥-----------
0.6089008766014835 0.6089008766014835 0.6089008766014835
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 4, 'min_samples_leaf': 1, 'min_samples_split': 10, 'n_estimators': 150}
성능평가결과[정확도] : 0.6265139384422073
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=4,
min_samples_split=10, n_estimators=150)
-------------prod_company-------------
----------냉장고-----------
0.7013076393668273 0.7013076393668273 0.7013076393668273
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 10, 'n_estimators': 50}
성능평가결과[정확도] : 0.6851027638583167
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=5,
min_samples_split=10, n_estimators=50)
----------tv-----------
0.6474239602731223 0.6474239602731223 0.6474239602731223
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 150}
성능평가결과[정확도] : 0.6681150424167184
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=5, n_estimators=150)
----------세탁기-----------
0.77947932618683 0.77947932618683 0.77947932618683
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 4, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 150}
성능평가결과[정확도] : 0.7651863195507912
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=4, min_samples_leaf=2,
min_samples_split=10, n_estimators=150)
----------에어컨-----------
0.7115127175368139 0.7115127175368139 0.7115127175368139
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 4, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 150}
성능평가결과[정확도] : 0.7179183355435587
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=4, n_estimators=150)
----------전기밥솥-----------
0.7302764666217127 0.7302764666217127 0.7302764666217127
최적의 파라메터들 : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 50}
성능평가결과[정확도] : 0.7334823113586202
최적의 모델 : GradientBoostingClassifier(learning_rate=0.01, max_depth=5, min_samples_leaf=2,
min_samples_split=10, n_estimators=50)

각각 종속변수와 각각의 제품 항목에 대한 최적의 모델(파라메터)를 저장하고 혼동행렬도를 시각화 하였습니다.
#혼동행렬도 시각화
def cm_plot(df):
fig , axs = plt.subplots(2,1,figsize=(15,10))
axs = axs.flatten()
for model,cm,ax in zip(df["모델이름"],df["혼동행렬"],axs):
sns.heatmap(cm,annot = True,fmt ="d",cmap = "Blues",
xticklabels=[0,1,2,3,4,5],yticklabels=[0,1,2,3,4,5],ax=ax)
ax.set_title(f"{model} 혼동행렬도")
plt.show()

[ 딥러닝 - DNN ]
○ 최적의 옵티마이저 찾기
# 최적의 옵티마이저 찾기
def best_op(cnt,ctcd,choice,X_train,y_train,X_val,y_val):
optimizer = ["sgd","adam","rmsprop","adagrad"]
history_loss = {}
history_acc = {}
for op in optimizer:
print(f"-------------[{op}]--------------")
model = keras.models.Sequential()
model.add(keras.layers.Dense(64,input_shape=(7,),activation="sigmoid"))
model.add(keras.layers.Dense(32,activation="sigmoid"))
model.add(keras.layers.Dense(cnt,activation="softmax"))
model.compile(
optimizer = op,
loss = "sparse_categorical_crossentropy",
metrics = ["accuracy"]
)
model_path = f"./model/{choice}_{ctcd}best_model_{op}.h5"
checkpoint_cb = keras.callbacks.ModelCheckpoint(
model_path,
save_best_only=True
)
early_stopping_cb = keras.callbacks.EarlyStopping(
patience = 3, restore_best_weights=True
)
history = model.fit(X_train,y_train,epochs=100,
validation_data=(X_val,y_val),
callbacks=[checkpoint_cb,early_stopping_cb])
history_loss[min(history.history['val_loss'])] = op
history_acc[max(history.history['val_accuracy'])] = op
print(f"---------------{ctcd}-------------------")
print(f"최적의 옵티마이저 : {history_loss[min(history_loss.keys())]} / 손실율 : {min(history_loss.keys())}")
print(f"최적의 옵티마이저 : {history_acc[max(history_acc.keys())]} / 정확도 : {max(history_acc.keys())}")df_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
df_best_all = pd.DataFrame()
df_total = pd.DataFrame()
for choice in choice_list:
print(f"-------------{choice}-------------")
n=0
for df in df_list:
print(f"----------{ctcd[n]}-----------")
X,y = sep(df,choice)
cnt = len(y.value_counts())
X_train,X_val,X_test,y_train,y_val,y_test = split(X,y)
best_op(cnt,ctcd[n],choice,X_train,y_train,X_val,y_val)
n+=1epoch = 100 일때 최적의 옵티마이저 → adam
------------prc_level-------------
---------------냉장고-------------------
최적의 옵티마이저 : adam / 손실율 : 0.780555784702301
최적의 옵티마이저 : adam / 정확도 : 0.6930488348007202
--------------tv-------------------
최적의 옵티마이저 : adam / 손실율 : 0.5761458873748779
최적의 옵티마이저 : adam / 정확도 0.8081936836242676
--------------세탁기-------------------
최적의 옵티마이저 : adam / 손실율 : 0.7987041473388672
최적의 옵티마이저 : adam / 정확도 0.6503317952156067
--------------에어컨-------------------
최적의 옵티마이저 : adam / 손실율 : 0.8132628798484802
최적의 옵티마이저 : rmsprop / 정확도0.6800535321235657
--------------전기밥솥-------------------
최적의 옵티마이저 : adam / 손실율 : 0.9575439095497131
최적의 옵티마이저 : adam / 정확도 : 0.6196898221969604
-------------prod_company-------------
--------------냉장고-------------------
최적의 옵티마이저 : adam / 손실율 : 0.7742734551429749
최적의 옵티마이저 : adam / 정확도 : 0.6978664994239807
--------------tv-------------------
최적의 옵티마이저 : adam / 손실율 : 0.9847794771194458
최적의 옵티마이저 : adam / 정확도 : 0.6412166357040405
--------------세탁기-------------------
최적의 옵티마이저 : rmsprop / 손실율 : 0.5378641486167908
최적의 옵티마이저 : adam / 정확도 : 0.7774374485015869
--------------에어컨-------------------
최적의 옵티마이저 : adam / 손실율 : 0.6129884719848633
최적의 옵티마이저 : rmsprop / 정확도 : 0.7108433842658997
--------------전기밥솥-------------------
최적의 옵티마이저 : adam / 손실율 : 0.8068097829818726
최적의 옵티마이저 : rmsprop / 정확도 : 0.708698570728302
○ 옵티마이저 adam 사용한 DNN 모델 생성 및 훈련
def adam_model(choice,ctcd,X_train,y_train,X_val,y_val):
# 최적의 옵티마이저 사용
# 모델 생성 및 훈련
df = pd.DataFrame()
best_model = keras.models.load_model(f"./model/{choice}_{ctcd}best_model_adam.h5")
y_pred = best_model.predict(X_val)
y_pred = np.argmax(y_pred,axis=1)
train_score = best_model.evaluate(X_train,y_train)
val_score = best_model.evaluate(X_val,y_val)
precision = precision_score(y_val, y_pred,average="micro")
recall = recall_score(y_val, y_pred,average="micro")
f1 = f1_score(y_val, y_pred,average="micro")
cm = confusion_matrix(y_val, y_pred)
df_eval = pd.DataFrame([[choice,ctcd,train_score,val_score,precision,recall,f1,cm]],columns=["구분","품목","훈련정확도","검증정확도","정밀도","재현율","f1-score","혼동행렬"])
df = pd.concat([df,df_eval],ignore_index=True)
return dfdf_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
df_adam_all = pd.DataFrame()
df_adam = pd.DataFrame()
for choice in choice_list:
print(f"-------------{choice}-------------")
n=0
for df in df_list:
print(f"----------{ctcd[n]}-----------")
X,y = sep(df,choice)
X_train,X_val,X_test,y_train,y_val,y_test = split(X,y)
df = adam_model(choice,ctcd[n],X_train,y_train,X_val,y_val)
n +=1
df_adam = pd.concat([df_adam,df],ignore_index=True)
df_adam_all = pd.concat([df_adam_all,df_adam],ignore_index=True) 
[ 테스트 데이터로 예측 및 성능 평가 ]
# 최적의 파라미터들 설정
# optimal_params = {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 50}
def test_eval_gb(choice,ctcd,optimal_params,X_train,y_train,X_test,y_test):
# GradientBoosting 모델 생성 및 최적의 파라미터 적용
gb_model = GradientBoostingClassifier(**optimal_params)
gb_model.fit(X_train,y_train)
# 모델 저장 추가 - joblib
joblib.dump(gb_model,f'./model/{choice}_{ctcd}gb_model.h5')
# 테스트 데이터로 예측하기,성능평가하기
gb_pred_train = gb_model.predict(X_train)
gb_pred = gb_model.predict(X_test)
gb_acc_train = accuracy_score(y_train,gb_pred_train)
gb_acc = accuracy_score(y_test,gb_pred)
gb_precision = precision_score(y_test,gb_pred,average="micro")
gb_recall = recall_score(y_test,gb_pred,average="micro")
gb_f1 = f1_score(y_test,gb_pred,average="micro")
gb_cm = confusion_matrix(y_test,gb_pred)
print(f"{choice}_{ctcd}_GB : {gb_acc_train} / {gb_acc} / {gb_precision} / {gb_recall} / {gb_f1}")
df_eval = pd.DataFrame([[choice,ctcd,gb_acc,gb_precision,gb_recall,gb_f1,gb_cm]],columns=["구분","품목","테스트정확도-gb","정밀도","재현율","f1-score","혼동행렬"])
print()
return df_eval
def test_eval_dnn(choice,ctcd,X_train,y_train,X_test,y_test):
# DNN
dnn_model = keras.models.load_model(f"./model/{choice}_{ctcd}best_model_adam.h5")
# 테스트 데이터로 예측하기,성능평가하기
y_pred_train = dnn_model.predict(X_train)
y_pred = dnn_model.predict(X_test)
dnn_pred_train = np.argmax(y_pred_train,axis=1)
dnn_pred = np.argmax(y_pred,axis=1)
dnn_acc_train = accuracy_score(y_train,dnn_pred_train)
dnn_acc = accuracy_score(y_test,dnn_pred)
dnn_precision = precision_score(y_test,dnn_pred,average="micro")
dnn_recall = recall_score(y_test,dnn_pred,average="micro")
dnn_f1 = f1_score(y_test,dnn_pred,average="micro")
dnn_cm = confusion_matrix(y_test,dnn_pred)
print(f"{choice}_{ctcd}_DNN : {dnn_acc} / {dnn_precision} / {dnn_recall} / {dnn_f1}")
df_eval = pd.DataFrame([[choice,ctcd,dnn_acc,dnn_precision,dnn_recall,dnn_f1,dnn_cm]],columns=["구분","품목","테스트정확도-dnn","정밀도","재현율","f1-score","혼동행렬"])
print()
return df_evaloptimal_params = {"prc_level" :
{"냉장고" : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 50},
"tv" : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 100},
"세탁기" : {'learning_rate': 0.2, 'max_depth': 4, 'min_samples_leaf': 4, 'min_samples_split': 2, 'n_estimators': 50} ,
"에어컨" : {'learning_rate': 0.01, 'max_depth': 4, 'min_samples_leaf': 4, 'min_samples_split': 2, 'n_estimators': 100},
"전기밥솥" : {'learning_rate': 0.01, 'max_depth': 4, 'min_samples_leaf': 1, 'min_samples_split': 10, 'n_estimators': 150}},
"prod_company" :
{"냉장고" : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 10, 'n_estimators': 50},
"tv" : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 150},
"세탁기" : {'learning_rate': 0.01, 'max_depth': 4, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 150} ,
"에어컨" : {'learning_rate': 0.01, 'max_depth': 4, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 150},
"전기밥솥" : {'learning_rate': 0.01, 'max_depth': 5, 'min_samples_leaf': 2, 'min_samples_split': 10, 'n_estimators': 50}}}
○ GradientBoosting 테스트데이터 성능 평가
df_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
df_best = pd.DataFrame()
df_total = pd.DataFrame()
for choice in choice_list:
print(f"-------------{choice}-------------")
n=0
for df in df_list:
print(f"----------{ctcd[n]}-----------")
X,y = sep(df,choice)
X_train,X_val,X_test,y_train,y_val,y_test = split(X,y)
print(X_train)

○ DNN 성능평가
df_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
df_best_dnn = pd.DataFrame()
df_total = pd.DataFrame()
for choice in choice_list:
print(f"-------------{choice}-------------")
n=0
for df in df_list:
print(f"----------{ctcd[n]}-----------")
X,y = sep(df,choice)
X_train,X_val,X_test,y_train,y_val,y_test = split(X,y)
optimal_param = optimal_params[choice][ctcd[n]]
df_eval = test_eval_dnn(choice,ctcd[n],X_test,y_test)
n+=1
df_total = pd.concat([df_total,df_eval],ignore_index=True)
df_best_dnn = pd.concat([df_best_dnn,df_total],ignore_index=True) 
▶ GradientBoosting 모델이 더 높은 정확도를 보이므로 최종 모델로 선정
[ 임의의 데이터로 예측하기 ]
○ 임의의 데이터 생성
data_dict = {
"user_gender": [1],
"user_address": [2],
"user_age": [60],
"user_family_counts": [2],
"buy_season": [2],
"buy_day": [5],
"buy_hour": [8]
}
data = pd.DataFrame(data_dict)
data
○ 예측하기
df_list = [df_ref,df_tv,df_wash,df_air,df_cooker]
choice_list = ["prc_level","prod_company"]
ctcd = ["냉장고","tv","세탁기","에어컨","전기밥솥"]
for choice in choice_list:
print(f"-------------{choice}-------------")
ctcd = "세탁기"
pred = predict_sample(choice,ctcd,data)
print(pred)-------------prc_level-------------
[2]
-------------prod_company-------------
[0]
'Project' 카테고리의 다른 글
| [스마트 IoT 홈 서비스] 챗봇 모델(1) - 모델 생성 (1) | 2024.02.16 |
|---|---|
| [전자제품쇼핑몰] Flask 사용하여 React에 제품 추천 서비스 구현하기 (2) | 2024.02.04 |
| [전자제품쇼핑몰] Flask 사용하여 python 파일과 react 연결하기 (0) | 2024.01.28 |
| [전자제품쇼핑몰] 로그데이터 분석 및 시각화 (1) | 2024.01.28 |
| [전자제품 쇼핑몰] 데이터베이스에 데이터 저장하기 & 데이터 생성하기 (1) | 2024.01.28 |