
1. 원본 데이터 적재
실습용 데이터로 AdventureWorks 샘플 DB는 2019년 자료를 사용하였습니다.
다운로드한 데이터 파일을 SSMS를 통해 Desktop DB에 백업하고 Target DB가 될 데이터 베이스에 테이블을 생성하였습니다.
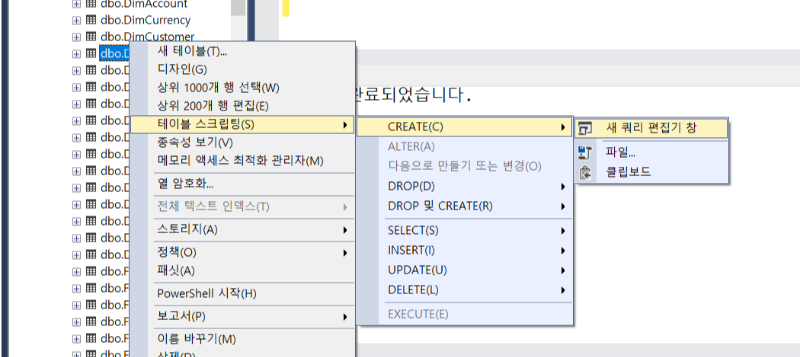
SSMS에서 원본 데이터의 테이블 우클릭 > 테이블 스크립팅 > CREATE > 새 쿼리 편집기 창을 통해
해당 테이블의 CREATE 문을 확인할 수 있습니다.
원본 데이터가 있는 DB를 편의상 Source DB라 칭하겠습니다.
create 구문을 사용하여 Target DB에 데이터가 없는 빈 테이블을 생성합니다.
이때 Create 구문에 Identity (1,1) 과 같이 자동으로 데이터를 생성해주는
IDENTITY [ (시작값, 증가값) ] 과 같은 구문이 있을때는 주의해야합니다. 원본 데이터와 그 값이 달라질 수 있습니다.
2. DB에 적재된 데이터 ETL
ETL은 크게 SSIS(Microsoft SQL Server Integration Services)와 ADE(Azure Data Factory ETL Tool)두 가지 방법이 있는데 SSIS는 On-premise 기반이고 ADF는 클라우드 기반이라고 한다.
Cloud
필요한 IT 자원만을 선택해 인터넷을 통해 서비스 방식으로 구입해 사용하는 방식
크게 세가지로 나뉨
SaaS( 서비스로서의 소프트웨어) : 소프트웨어를 웹에서 사용할 수 있는 서비스로 소프트웨어를 소유하지 않고 웹 브라우저를 통해 사용하는 서비스로 구글 드라이브 같은 서비스
IaaS( 서비스로서의 인프라) : 인터넷을 통해 가상 서버와 데이터 스토리지 같은 데이터 자원을 빌려 사용할 수 있는 서비스 ,AWS 자원 빌려 넷플릭스 운영
PaaS(서비스로서의 플랫폼) : 소프트웨어를 개발할 때 필요한 플랫폼을 제공하는 서비스 개발자가 개발환경을 위해 필요한 하드웨어나 소프트웨어의 구축없이 개발하고 구축하고 실행하는데 필요한 개발도구와 환경을 제공하는 서비스로 구글 앱 엔진이 해당됨
On-premise
기업의 서버를 클라우드 같은 원격 환경에서 운영하는 방식이 아닌, 자체적으로 보유한 전산실 서버에 직접 설치해 운영하는 방식을 의미함
장점은 기업의 비즈니스 정보를 보안성 높게 관리할 수 있다는 것
단점은 시스템을 구축하는데 있어서 많은 시간과 비용이 소요된다는 것
< 차이점>
| 클라우드 | 온프레미스 | |
| 1. 비용 | 초기 투자 비용 없음 구독형/충전형 요금제 데이터 증가 시 추가적인 비용 발생 |
높은 초기 구축 비용 데이터로 인한 추가 비용 적음 장기적으로 사용 시 비용 효율 높음 |
| 2. 보안 | 클라우드 서비스 제공 업체의 보안 시스템 | 기업 자체의 보안 시스템 적용 |
| 3. 구축 및 관리 | 신속한 도입 가능 관리를 위한 별도의 전문 인력 불필요 |
시스템 구축에 별도의 시간 필요 필요에 따라 맞춤형으로 구축 가능 인프라를 관리를 위한 전담 인력 및 조직 필요 |
○ SSIS 를 사용하여 ETL
SSIS 참고 사이트
https://www.tutorialgateway.org/ssis/
SSIS :
다양한 소스에서 데이터를 추출하고 사용자 요구사항에 따라 해당 데이터를 변환한 다음 데이터를 다양한 대상으로 로드함
ETL : 추출(Extract), 변환(Transform), 로드(Load)를 나타내며 조직에서 여러 시스템의 데이터를 단일 데이터베이스, 데이터 저장소, 데이터 웨어하우스 또는 데이터 레이크에 결합하기 위해 일반적으로 허용되는 방법
1. Integration Service Project 선택
2. 연결관리자를 통해 데이터베이스(서버) 연결
연결관리자 :
데이터베이스에서 테이블을 추출하거나 데이터 웨어하우스에 행을 로드하거나 데이터베이스에서 텍스트나 excel 파일로 또는 그 반대로 레코드를 전송하는 등의 행위를 수행하기 위해 필요함
>> OLE DB, 플랫파일 , ADO.NET 등 해당하는 연결관리자 선택
- ADO.NET 연결 > Desktop 서버 연결 > Source DB로 이름 변경(선택)
- ADO.NET 연결 > 타겟서버 연결 > Target DB로 이름 변경(선택)
- 제어 흐름 창에 sql 실행 태스크 , 데이터 흐름 태스크 추가 >> 이것이 하나의 패키지가 됨

3. ADO NET 원본 > 편집 > Source DB의 옮길 데이터 테이블을 선택 ,
ADO NET 대상 > 편집 > Target DB의 데이터를 적재할 테이블 선택
>> 화살표로 연결
4. SQL 실행 태스크
>> Connection Type : ADO.NET / Connection : TargetDB
>> 이때 외래키때문에 오류발생할 수 있음 외래키 없는 테이블 생성 필요
패키지 실행하면 데이터가 적재되는데 이때 중복 데이터 생성 방지를 위해
데이터를 삭제해주는 작업이 필요하다
이를 위해 TRUNCATE 구문을 사용한다
>> SQLStatement 에 Truncate구문 작성 : TRUNCATE TABLE [테이블명]

5. 위와 같이 하나의 테이블의 데이터를 이관하는 하나의 패키지에
하나의 (SQL + 데이터 태스크) 흐름을 두고
테이블개수만큼 패키지를 복사하여 생성 후
전체 패키지를 실행하는 하나의 패키지를 생성하여
패키지 실행 태스크를 통해 데이터를 적재한다

○ ADF(Azure Data Factory) 를 사용하여 ETL
Azure : 클라우딩 서비스 , 웹상에서 ETL 가능
- 리소스 만들기 > Data Factory
리소스 항목에서 생성된 것을 확인할 수 있음 - 생성된 Data Factory > Studio 시작하기
- 통합 런타임 > 새로만들기 > Self Hosted > 수동 설치 > 인증 키 (key1) 를 통해 인증하면
클라우드와 PC가 연결됨
: Integration Runtime 필요 >> 클라우드 환경에서 On-Premise 환경과 연결하기 위해 - 연결된 서비스(연결관리자) > 새로만들기 > sql 서버 > Source DB와 Target DB를 연결해준다.
이때 DeskTop의 아이디와 비밀번호는 SSMS 참고 및 사용자 로그인 비밀번호
Target DB는 동일하지만 IR을 생성한 IR이 아닌 AutoResolveIntegrationRuntime 로 설정해줌
윈도우 인증 안되면 sql 인증으로하기 > 그러나 보통은 Sql 인증 - 데이터 세트 (임시 저장)
매개변수는 스키마와 테이블 >> SCHEMA_NM , TABLE_NM - 파이프라인 생성 (SSIS의 패키지와 같은 역할)
데이터 복사 > 원본에 source , 싱크에 target
일부분만 가지고오고싶다면 쿼리 선택 후 쿼리문으로 select
>> 또는 전체 파이프라인에 매개변수 두개 (스키마, 테이블) 이후에 동적 컨텐츠로 가져오기
Select * from @{ 스키마}.@{테이블}
사전복사 스크립트에 > truncate table @ 스키마. @ 테이블
Ex) Truncate Table @{pipeline().parameters.SCHEMA_NM}.@{pipeline().parameters.TABLE_NM}
Fact 데이터는 Delete > 중복 방지
Dimension 데이터는 Truncate
++ 테이블 자동 만들기는특별한 경우 아니면 사용하지 않음
매핑으로 맞게 연결되었는지 확인
매개변수 사용시 편리함 >> 그 값만 바꿔주면됨
ETL 수정시각 포함해주라는 요청사항
: 원본 > 추가열 > 열 이름 만들고 사용자 지정 또는 동적 콘텐츠로 날짜 추가가능
트리거 : 자동으로 수행되게 하는것 >> 관리 영역
트리거 > 새로만들기 > 간격 지정(시간대)
3. Azure SQL Server로 이관한 데이터를 정제하여 Power BI에서 사용 가능한 Data Mart (SQL View) 구축
View 생성 : CREATE VIEW [뷰명] AS SELECT [컬럼명] FROM [테이블명] WHERE [조건절]
아래와 같이 Join 조건에 맞추어 주어진 View 정보에 따라 View를 생성했습니다.
CREATE VIEW [dbo].[DIM_Products] AS
SELECT ProductKey
, ProductAlternateKey AS ProductItemCode
, EnglishProductName AS ProductName
, EnglishProductSubcategoryName AS SubCatagory
, EnglishProductCategoryName AS ProductCategory
, Color AS ProductColor
, Size AS ProductSize
, ProductLine
, ModelName AS ProductModelName
, EnglishDescription AS ProductDescription
, ISNULL([Status] , 'Outdated' ) AS ProductStatus
FROM Dimproduct AS p
LEFT JOIN DimproductSubCategory AS psc ON p.ProductSubcategoryKey = psc.ProductSubcategoryKey
LEFT JOIN DimproductCategory AS pc ON psc.ProductSubCategoryKey = pc.ProductCategoryKey
추후에 Power BI에서 데이터 가져오기를 통해 View 데이터를 토대로 보고서를 작성하면됩니다.
'Power BI' 카테고리의 다른 글
| Power BI 보고서 작성 # 2 (2) | 2024.04.25 |
|---|---|
| Power BI 보고서 작성 # 1 (0) | 2024.04.24 |
| DAX 함수 및 파워쿼리편집기를 통한 측정값 #3 (4) | 2024.04.17 |
| DAX 함수 및 파워쿼리편집기를 통한 측정값 #2 (0) | 2024.04.16 |
| DAX 함수 및 파워쿼리 편집기를 통한 측정값 #1 (0) | 2024.04.15 |