
○ Placements
You are given three tables: Students, Friends and Packages. Students contains two columns: ID and Name. Friends contains two columns: ID and Friend_ID (ID of the ONLY best friend). Packages contains two columns: ID and Salary (offered salary in $ thousands per month).
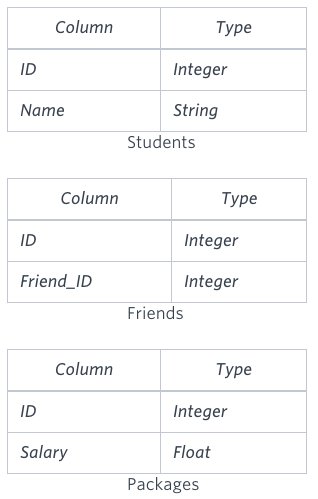
Write a query to output the names of those students whose best friends got offered a higher salary than them. Names must be ordered by the salary amount offered to the best friends. It is guaranteed that no two students got same salary offer.
[ 나의 풀이 ]
select S.Name
from Friends as F join Packages as P on F.ID = P.ID
join Packages as PS on F.Friend_ID = PS.ID
join Students as S on F.ID = S.ID
where P.Salary < PS.Salary
order by PS.Salary
동일한 Packages 테이블을 두번 Join 해준다.
하나는 Packages의 ID가 Friends 테이블의 ID와 같다는 조건, 다음은 Friend_ID와 같다는 조건으로 Join하여
ID 즉 본인의 Salary와 Friend의 Salary를 구하였다. 이를 where 구문을 통해 비교하여 친구보다 적은 Salary를 받는 경우에만 출력하도록 하고 Students 테이블과 Join을 통해 이름을 표현하도록 하면 된다.
○ Symmetric Pairs
You are given a table, Functions, containing two columns: X and Y.
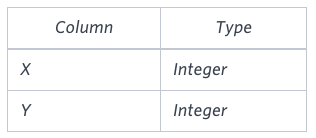
Two pairs (X1, Y1) and (X2, Y2) are said to be symmetric pairs if X1 = Y2 and X2 = Y1.
Write a query to output all such symmetric pairs in ascending order by the value of X. List the rows such that X1 ≤ Y1.
Sample Input
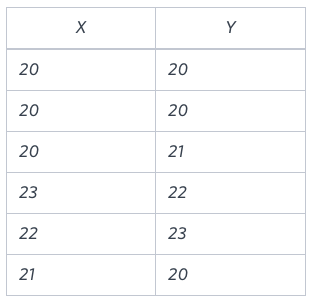
[ 나의 풀이 ]
select distinct F1.X , F1.Y
from Functions as F1 join Functions as F2 on F1.X = F2.Y
where (F1.Y = F2.X
and F1.X <> F1.Y
and F1.X < F1.Y)
or (F1.Y = F2.X
and F1.X in (select F1.X
from Functions as F1 join Functions as F2 on F1.X = F2.Y
where F1.Y = F2.X
and F1.X = F1.Y
group by F1.X
having count(*) > 1)
)
서브쿼리를 사용했다
Functions 테이블을 Self Join하여 F1의 X와 F2의 Y가 같은 경우와 where절로 그 반대로 동일한 경우 조건을 걸어주고
이때 X,Y가 같은 경우를 제외하고 X가 Y보다 작은 경우만 반환한다.
또한 X, Y가 같은 경우가 두개 있는 경우에는 반환할 수 있도록 서브쿼리로 해당하는 X를 반환하도록 하여
or 로 추가해준다.
○ Print Prime Numbers
Write a query to print all prime numbers less than or equal to 1000 . Print your result on a single line, and use the ampersand () character as your separator (instead of a space).
For example, the output for all prime numbers <= 10 would be:
2&3&5&7
소수 반환하기
[ 나의 풀이 ]
DECLARE @i bigint = 2;
DECLARE @result NVARCHAR(1000) = "2";
WHILE @i < 1000
BEGIN
SET @i = @i + 1
DECLARE @j bigint = 2;
DECLARE @cnt bigint = 0;
WHILE @j < @i
BEGIN
IF (@i % @j = 0)
BEGIN
SET @cnt = @cnt + 1
END
SET @j = @j + 1
END
IF (@cnt = 0)
BEGIN
SET @result =@result+"&"+LTRIM(STR(@i))
END
END
PRINT @result
선언의 위치에 따라 값이 달라질 수 있음
SQL으로 반복문 생성은 처음이라 헷갈렸다.

While 또는 IF 구문으로 나눠보자면 왼쪽 사진과 같다
@j와 @cnt는 @i의 값이 1씩 커질때마다
다시 원래의 기본값으로 돌아가야되기 때문에 while 문 안에서 @i에 1씩 더한 후에 선언해줬다
이후에 두번째 내부 while에서 @j가 @i보다 작은 경우에 IF문으로 나누어 떨어지는 수가 있으면 @cnt에 1씩 더해주고 그 다음 @cnt가 0이면 나누어 떨어지는 값이 없다는 뜻이므로 이때 @result에 값을 붙여 출력되도록 했다
이때 STR은 공백있이 문자열로 변환되므로 LTRIM으로 공백을 제거하였다.
마지막 while문 밖에서 @result를 PRINT하면 아래와 같은 결과를 얻을 수 있다.
2&3&5&7&11&13&17&19&23&29&31&37&41&43&47&53&59&61&67&71&73&79&83&89&97&101&103&107&109&113&127&131&137&139&149&151&157&163&167&173&179&181&191&193&197&199&211&223&227&229&233&239&241&251&257&263&269&271&277&281&283&293&307&311&313&317&331&337&347&349&353&359&367&373&379&383&389&397&401&409&419&421&431&433&439&443&449&457&461&463&467&479&487&491&499&503&509&521&523&541&547&557&563&569&571&577&587&593&599&601&607&613&617&619&631&641&643&647&653&659&661&673&677&683&691&701&709&719&727&733&739&743&751&757&761&769&773&787&797&809&811&821&823&827&829&839&853&857&859&863&877&881&883&887&907&911&919&929&937&941&947&953&967&971&977&983&991&997
○ Interviews
Samantha interviews many candidates from different colleges using coding challenges and contests. Write a query to print the contest_id, hacker_id, name, and the sums of total_submissions, total_accepted_submissions, total_views, and total_unique_views for each contest sorted by contest_id. Exclude the contest from the result if all four sums are .
Note: A specific contest can be used to screen candidates at more than one college, but each college only holds screening contest.
Input Format
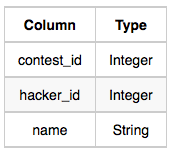
The following tables hold interview data:
- Contests: The contest_id is the id of the contest, hacker_id is the id of the hacker who created the contest, and name is the name of the hacker.
- Colleges: The college_id is the id of the college, and contest_id is the id of the contest that Samantha used to screen the candidates.
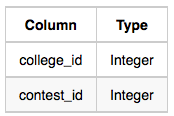
- Challenges: The challenge_id is the id of the challenge that belongs to one of the contests whose contest_id Samantha forgot, and college_id is the id of the college where the challenge was given to candidates.
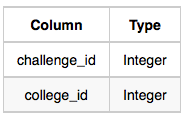
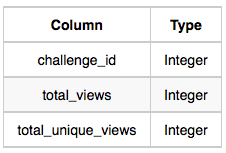
- View_Stats: The challenge_id is the id of the challenge, total_views is the number of times the challenge was viewed by candidates, and total_unique_views is the number of times the challenge was viewed by unique candidates.
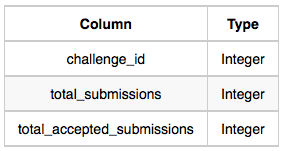
- Submission_Stats: The challenge_id is the id of the challenge, total_submissions is the number of submissions for the challenge, and total_accepted_submission is the number of submissions that achieved full scores.
한 사람 당 하나의 콘테스트 (contests 테이블은 중복이 없음)
하나의 대학에 하나의 콘테스트
콘테스트 하나에 여러개의 대학
챌린지는 중복없음 하나의 챌린지에 하나의 대학
대학 하나에 여러개의 챌린지
[ 나의 풀이]
with cte as (
select ct.contest_id, ct.hacker_id, ct. name, ch.challenge_id
from contests ct join colleges cg on ct.contest_id = cg.contest_id
join challenges ch on cg.college_id = ch.college_id ),
cte_vs as ( select challenge_id, sum(total_views) as total_views, sum(total_unique_views) as total_unique_views
from view_stats group by challenge_id ),
cte_ss as ( select challenge_id, sum(total_submissions) as total_submissions, sum(total_accepted_submissions) as total_accepted_submissions
from submission_stats group by challenge_id )
select contest_id, hacker_id, name, sum(total_submissions), sum(total_accepted_submissions), sum(total_views), sum(total_unique_views)
from cte left join cte_vs on cte.challenge_id = cte_vs.challenge_id
left join cte_ss on cte.challenge_id = cte_ss.challenge_id
group by contest_id, hacker_id, name
order by contest_id
Contests , Colleges , Challenges를 join으로 연결한 cte
Challenges left join으로 View_Stats 연결한 cte_vs와 Submissions_Stats 연결한 cte_ss
-> Challenges가 존재하지 않은 경우를 제외하기 위해 left join 사용
세 cte 가상 테이블을 사용하여 left join 후
contest_id , hacker_id , name으로 그룹화 한 뒤 contest_id 기준으로 정렬하여 각각의 sum 값 구하면 됨
○ Draw The Triangle 1
P(R) represents a pattern drawn by Julia in R rows. The following pattern represents P(5):
* * * * *
* * * *
* * *
* *
*Write a query to print the pattern P(20).
[ 나의 풀이 ]
DECLARE @i BIGINT = 20
WHILE @i > 0
BEGIN
PRINT REPLICATE("* ", @i)
SET @i = @i - 1
END
While 문을 사용하여 1씩 작아지는 숫자 만들기
REPLICATE(문자열 , 반복횟수) 로 숫자 만큼 "*" 이 반복 출력되도록 하기
○ Draw The Triangle 2
P(R) represents a pattern drawn by Julia in R rows. The following pattern represents P(5):
*
* *
* * *
* * * *
* * * * *
Write a query to print the pattern P(20).
[ 나의 풀이 ]
DECLARE @i BIGINT = 1
WHILE @i <= 20
BEGIN
PRINT REPLICATE("* " , @i)
SET @i = @i + 1
END
이전 문제와 반대로 1부터 지정 숫자 20까지 1씩 커지면서 "*" 를 반복하도록 작성하였다.
○ 15 Days of Learning SQL
Julia conducted a days of learning SQL contest. The start date of the contest was March 01, 2016 and the end date was March 15, 2016.
Write a query to print total number of unique hackers who made at least submission each day (starting on the first day of the contest), and find the hacker_id and name of the hacker who made maximum number of submissions each day. If more than one such hacker has a maximum number of submissions, print the lowest hacker_id. The query should print this information for each day of the contest, sorted by the date.
Input Format
The following tables hold contest data:
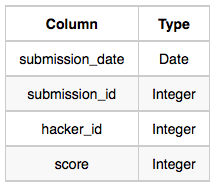
- Hackers: The hacker_id is the id of the hacker, and name is the name of the hacker.

- Submissions: The submission_date is the date of the submission, submission_id is the id of the submission, hacker_id is the id of the hacker who made the submission, and score is the score of the submission.
Sample Input
For the following sample input, assume that the end date of the contest was March 06, 2016.
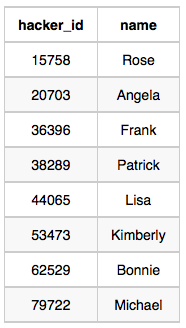
Hackers Table:
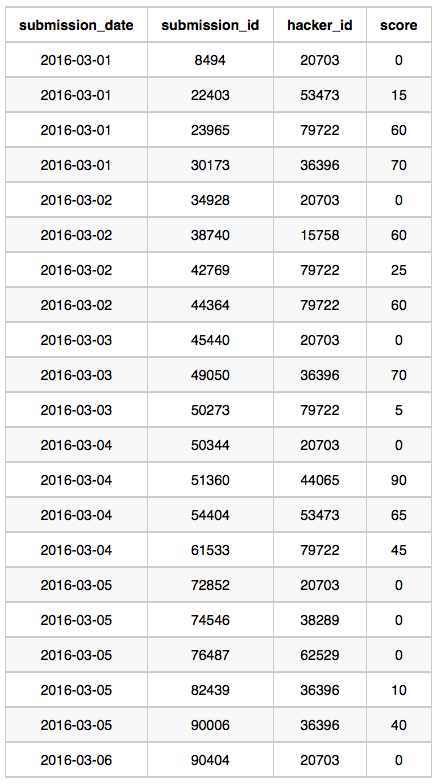
Submissions Table:
Sample Output
2016-03-01 4 20703 Angela
2016-03-02 2 79722 Michael
2016-03-03 2 20703 Angela
2016-03-04 2 20703 Angela
2016-03-05 1 36396 Frank
2016-03-06 1 20703 Angela[ 나의 풀이 ]
with cte_base as(
select distinct submission_date , hacker_id
from Submissions),
cte_flag as(
select * , sum(1) over(partition by hacker_id order by submission_date) as flag
from cte_base),
cte_cnt as(
select submission_date ,count(hacker_id) as cnt
from cte_flag
where day(submission_date) = flag
group by submission_date),
cte_base2 as(
select submission_date , hacker_id , sum(1) over(partition by submission_date , hacker_id ) as n
from Submissions),
cte_max as(
select submission_date , max(n) as maxn
from cte_base2
group by submission_date),
cte_maxhac as(
select cb2.submission_date , min(hacker_id) as hacker_id
from cte_base2 as cb2 join cte_max as cm on cb2.submission_date = cm.submission_date
where n = maxn
group by cb2.submission_date)
select cmh.submission_date , cc.cnt, cmh.hacker_id , H.name
from cte_maxhac as cmh join Hackers as H on cmh.hacker_id = H.hacker_id
join cte_cnt as cc on cmh.submission_date = cc.submission_date
order by cmh.submission_date
CTE 가상 테이블을 총 6개를 생성해서 풀었다.
문제는 첫 시작일부터 끝나는 날까지 해당 날짜까지 매일 제출한 사람 수 구하기( 6일이면 1일부터 6일까지 매일 제출한 사람 합) 과 해당 날짜에 제출한 사람 중 가장 많이 제출한 사람 또는 제출 개수가 동일하면 hacker_id가 작은 사람을 이름까지 반환하기 두 가지로 나누어서 풀었다.
먼저 base부터 cnt까지는 매일 제출한 사람의 합계를 구하는 것으로
cte_base에서 날짜와 해커 아이디 고유 값을 기준으로하는 테이블을 생성하였다
다음으로 cte_flag에서 sum(1) over(partition by hacker_id order by submission_date)를 통해 날짜 기준으로 특정 해커 유무에 따라 1씩 더해지도록 하는 flag를 생성했다.
이 후 flag에 따라 날짜 1일이면 1 , 15일 이면 15로 flag가 날짜와 동일한 경우의 해커 수를 count하는 cte_cnt를 생성했다.
다음으로 base2부터는 하루 중 해커의 제출 개수를 나타내기 위해 sum over를 사용하였다.
cte_max에서 일별 제출 개수가 가장 큰 제출개수를 구하고 그 제출개수를 가진 해커를 cte_maxhac에서 조회할 수 있도록 하였다.
생성한 cte 가상 테이블을 기반으로 Hackers를 join하여 name을 구하는 것과 , 필요한 값을 조회할 수 있도록 가상 테이블과의 join 을 하여 해결하였다.
'MS SQL' 카테고리의 다른 글
| MS SQL IF, WHILE , 프로시저 (0) | 2024.06.24 |
|---|---|
| Hacker Rank 문제풀이 #3 (0) | 2024.05.24 |
| Hacker Rank 문제풀이 #2 (0) | 2024.04.16 |
| Hacker Rank 문제 풀이 #1 (1) | 2024.04.15 |
| MS SQL 실습 및 추가 공부 내용 (1) | 2024.04.12 |