
1. 크레인 인형뽑기게임
문제 설명
게임개발자인 "죠르디"는 크레인 인형뽑기 기계를 모바일 게임으로 만들려고 합니다.
"죠르디"는 게임의 재미를 높이기 위해 화면 구성과 규칙을 다음과 같이 게임 로직에 반영하려고 합니다.

게임 화면은 "1 x 1" 크기의 칸들로 이루어진 "N x N" 크기의 정사각 격자이며 위쪽에는 크레인이 있고 오른쪽에는 바구니가 있습니다. (위 그림은 "5 x 5" 크기의 예시입니다). 각 격자 칸에는 다양한 인형이 들어 있으며 인형이 없는 칸은 빈칸입니다. 모든 인형은 "1 x 1" 크기의 격자 한 칸을 차지하며 격자의 가장 아래 칸부터 차곡차곡 쌓여 있습니다. 게임 사용자는 크레인을 좌우로 움직여서 멈춘 위치에서 가장 위에 있는 인형을 집어 올릴 수 있습니다. 집어 올린 인형은 바구니에 쌓이게 되는 데, 이때 바구니의 가장 아래 칸부터 인형이 순서대로 쌓이게 됩니다. 다음 그림은 [1번, 5번, 3번] 위치에서 순서대로 인형을 집어 올려 바구니에 담은 모습입니다.
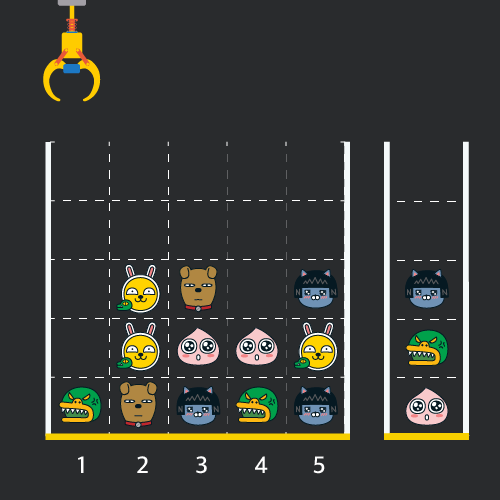
만약 같은 모양의 인형 두 개가 바구니에 연속해서 쌓이게 되면 두 인형은 터뜨려지면서 바구니에서 사라지게 됩니다. 위 상태에서 이어서 [5번] 위치에서 인형을 집어 바구니에 쌓으면 같은 모양 인형 두 개가 없어집니다.
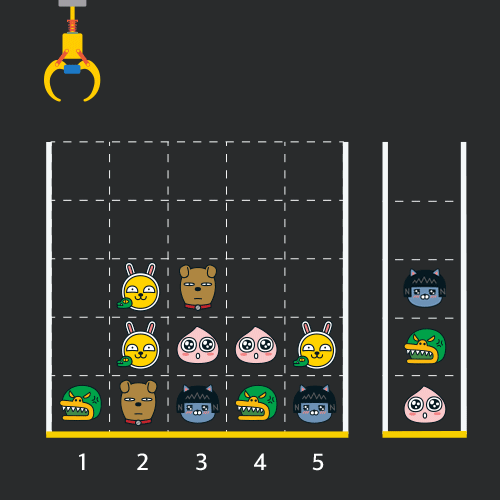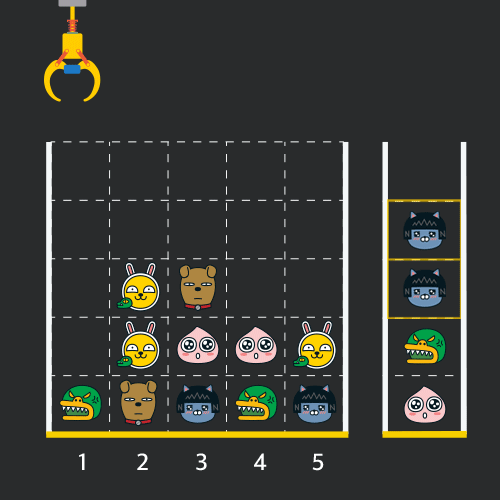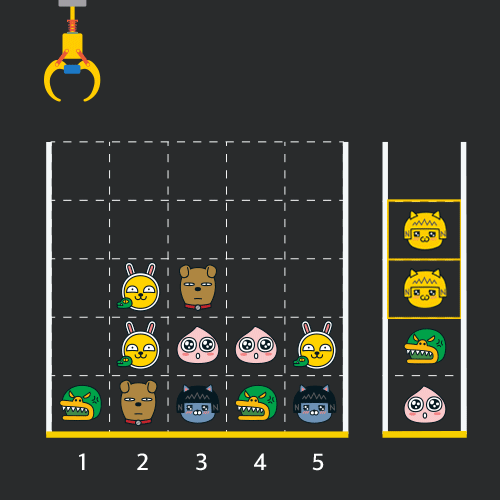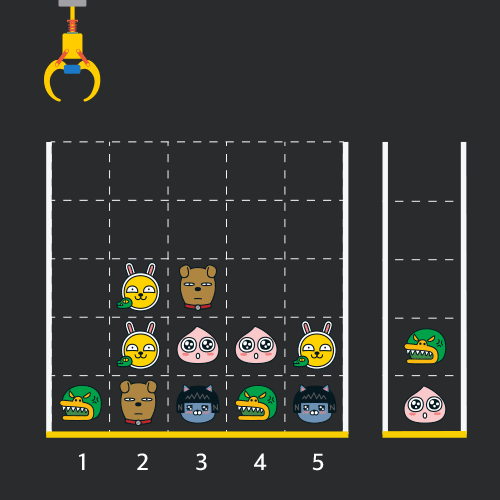
크레인 작동 시 인형이 집어지지 않는 경우는 없으나 만약 인형이 없는 곳에서 크레인을 작동시키는 경우에는 아무런 일도 일어나지 않습니다. 또한 바구니는 모든 인형이 들어갈 수 있을 만큼 충분히 크다고 가정합니다. (그림에서는 화면표시 제약으로 5칸만으로 표현하였음)
게임 화면의 격자의 상태가 담긴 2차원 배열 board와 인형을 집기 위해 크레인을 작동시킨 위치가 담긴 배열 moves가 매개변수로 주어질 때, 크레인을 모두 작동시킨 후 터트려져 사라진 인형의 개수를 return 하도록 solution 함수를 완성해주세요.
나의 풀이
def solution(board, moves):
basket = []
cnt = 0
for i in moves:
i -= 1
for j in range(len(board)):
if board[j][i] != 0 :
if len(basket)>0 and basket[-1] == board[j][i]:
basket.pop(-1)
cnt+=1
else:
basket.append(board[j][i])
board[j][i] = 0
break
return cnt*2
처음에 board 내의 리스트가 첫번째 줄, 두번째 줄 순서로 되어있는 것(세로 방향)으로 이해했는데, 알고보니 가로방향으로 위부터 확인할 수 있게 되어있는 문제였다.
로직은 board의 값이 0이 아닌 경우에 basket에 하나라도 인형이 있다면 basket의 제일 상단의 값과 board의 값을 비교하고, 동일하면 basket의 가장 위에 있는 값을 제거한다. 만약 동일하지 않은 값이라면 board의 값을 basket에 append 해준다.
이후 해당 board의 값은 0으로 변경하여 없는 값으로 인식되도록 한다.
board와 basket의 값이 동일한 경우 cnt +=1을 해주고 이를 2배하여 사라진 인형 개수를 return한다.
2. 키패드 누르기
문제 설명
스마트폰 전화 키패드의 각 칸에 다음과 같이 숫자들이 적혀 있습니다.

이 전화 키패드에서 왼손과 오른손의 엄지손가락만을 이용해서 숫자만을 입력하려고 합니다.
맨 처음 왼손 엄지손가락은 * 키패드에 오른손 엄지손가락은 # 키패드 위치에서 시작하며, 엄지손가락을 사용하는 규칙은 다음과 같습니다.
- 엄지손가락은 상하좌우 4가지 방향으로만 이동할 수 있으며 키패드 이동 한 칸은 거리로 1에 해당합니다.
- 왼쪽 열의 3개의 숫자 1, 4, 7을 입력할 때는 왼손 엄지손가락을 사용합니다.
- 오른쪽 열의 3개의 숫자 3, 6, 9를 입력할 때는 오른손 엄지손가락을 사용합니다.
- 가운데 열의 4개의 숫자 2, 5, 8, 0을 입력할 때는 두 엄지손가락의 현재 키패드의 위치에서 더 가까운 엄지손가락을 사용합니다.
4-1. 만약 두 엄지손가락의 거리가 같다면, 오른손잡이는 오른손 엄지손가락, 왼손잡이는 왼손 엄지손가락을 사용합니다.
순서대로 누를 번호가 담긴 배열 numbers, 왼손잡이인지 오른손잡이인 지를 나타내는 문자열 hand가 매개변수로 주어질 때, 각 번호를 누른 엄지손가락이 왼손인 지 오른손인 지를 나타내는 연속된 문자열 형태로 return 하도록 solution 함수를 완성해주세요.
나의 풀이
def index(x):
n_li = [1,2,3,4,5,6,7,8,9,"*",0,"#"]
n = n_li.index(x)
return [n%3 , n//3]
def cal(x,y):
cnt = abs(x[0]-y[0])+abs(x[1]-y[1])
return cnt
def solution(numbers, hand):
answer = ''
L = "*"
R = "#"
H = hand[0].upper()
for i in numbers:
if i in (1,4,7):
answer += "L"
L = i
elif i in (3,6,9):
answer += "R"
R = i
else :
I_index = index(i)
L_index = index(L)
R_index = index(R)
if cal(I_index , L_index) == cal(I_index, R_index):
answer += H
if H == "L":
L=i
else:
R=i
elif cal(I_index , L_index) > cal(I_index, R_index):
answer += "R"
R = i
else:
answer += "L"
L = i
return answer
약간 복잡하게 풀은 것 같지만..
우선 index , cal 함수는 중복되는 계산에 사용하기 위해 만든 것이고,
로직은 numbers의 숫자를 하나씩 for문으로 꺼내서 1,4,7에 속하면 L , 3,6,9에 속하면 R을 answer 문자열 뒤에 잇는다.
가운데 숫자의 경우 n_li 리스트에서 인덱스를 구한다.
| 0,0 | 1,0 | 2,0 |
| 1,0 | 1,1 | 2,1 |
| 2,0 | 1,2 | 2,2 |
| 3,0 | 1,3 | 2,3 |
위와 같이 인덱스 지정되도록 3으로 나눈 나머지와 몫을 사용하여 구하였다.
각각 가운데 숫자의 인덱스, 왼손과 오른손이 속한 인덱스를 뺀것의 절댓값을 비교하여 작은 쪽의 손으로 선택되도록 하였고, 값이 동일하면 hand의 첫번째 글자 대문자로 변환한 H 변수가 입력되도록 하였다.
3. 성격 유형 검사하기
문제 설명
나만의 카카오 성격 유형 검사지를 만들려고 합니다.
성격 유형 검사는 다음과 같은 4개 지표로 성격 유형을 구분합니다. 성격은 각 지표에서 두 유형 중 하나로 결정됩니다.
지표 번호성격 유형
| 1번 지표 | 라이언형(R), 튜브형(T) |
| 2번 지표 | 콘형(C), 프로도형(F) |
| 3번 지표 | 제이지형(J), 무지형(M) |
| 4번 지표 | 어피치형(A), 네오형(N) |
4개의 지표가 있으므로 성격 유형은 총 16(=2 x 2 x 2 x 2)가지가 나올 수 있습니다. 예를 들어, "RFMN"이나 "TCMA"와 같은 성격 유형이 있습니다.
검사지에는 총 n개의 질문이 있고, 각 질문에는 아래와 같은 7개의 선택지가 있습니다.
- 매우 비동의
- 약간 비동의
- 모르겠음
- 약간 동의
- 동의
- 매우 동의
각 질문은 1가지 지표로 성격 유형 점수를 판단합니다.
예를 들어, 어떤 한 질문에서 4번 지표로 아래 표처럼 점수를 매길 수 있습니다.
| 선택지성격 | 유형 점수 |
| 매우 비동의 | 네오형 3점 |
| 비동의 | 네오형 2점 |
| 약간 비동의 | 네오형 1점 |
| 모르겠음 | 어떤 성격 유형도 점수를 얻지 않습니다 |
| 약간 동의 | 어피치형 1점 |
| 동의 | 어피치형 2점 |
| 매우 동의 | 어피치형 3점 |
이때 검사자가 질문에서 약간 동의 선택지를 선택할 경우 어피치형(A) 성격 유형 1점을 받게 됩니다. 만약 검사자가 매우 비동의 선택지를 선택할 경우 네오형(N) 성격 유형 3점을 받게 됩니다.
위 예시처럼 네오형이 비동의, 어피치형이 동의인 경우만 주어지지 않고, 질문에 따라 네오형이 동의, 어피치형이 비동의인 경우도 주어질 수 있습니다.
하지만 각 선택지는 고정적인 크기의 점수를 가지고 있습니다.
- 매우 동의나 매우 비동의 선택지를 선택하면 3점을 얻습니다.
- 동의나 비동의 선택지를 선택하면 2점을 얻습니다.
- 약간 동의나 약간 비동의 선택지를 선택하면 1점을 얻습니다.
- 모르겠음 선택지를 선택하면 점수를 얻지 않습니다.
검사 결과는 모든 질문의 성격 유형 점수를 더하여 각 지표에서 더 높은 점수를 받은 성격 유형이 검사자의 성격 유형이라고 판단합니다. 단, 하나의 지표에서 각 성격 유형 점수가 같으면, 두 성격 유형 중 사전 순으로 빠른 성격 유형을 검사자의 성격 유형이라고 판단합니다.
질문마다 판단하는 지표를 담은 1차원 문자열 배열 survey와 검사자가 각 질문마다 선택한 선택지를 담은 1차원 정수 배열 choices가 매개변수로 주어집니다. 이때, 검사자의 성격 유형 검사 결과를 지표 번호 순서대로 return 하도록 solution 함수를 완성해주세요.
나의 풀이
def solution(survey, choices):
answer = ''
test = [['R','T'],['C','F'],['J','M'],['A','N']]
dict = {k: 0 for i in test for k in i}
for s , c in zip(survey, choices):
c -= 4
if c <0:
dict[s[0]] += abs(c)
elif c > 0:
dict[s[1]] += c
for i in test:
if dict[i[0]] < dict[i[1]]:
answer += i[1]
else:
answer += i[0]
return answer
survey의 지표들을 순서대로 오름차순 형태로 가지고 있는 리스트 test와 각 지표별 점수 정보를 가지고 있는 dict 를 생성하였다. 점수 기본값은 0으로 하고,
for문을 통해 survey와 choices를 순서대로 내보내어 choice의 점수에서 4를 뺀 것이 음수일때는 앞의 지표에 점수를, 양수일때는 뒤의 지표에 점수를 각각 절댓값만큼 더해주도록 하였다.
이후 test 리스트의 지표들 중 뒤의 지표 점수가 앞의 지표 점수보다 큰 경우를 제외하고는 앞의 지표가 성격 유형 정답 문자열에 포함되도록 하였다.
4. 데이터 분석
문제 설명
AI 엔지니어인 현식이는 데이터를 분석하는 작업을 진행하고 있습니다. 데이터는 ["코드 번호(code)", "제조일(date)", "최대 수량(maximum)", "현재 수량(remain)"]으로 구성되어 있으며 현식이는 이 데이터들 중 조건을 만족하는 데이터만 뽑아서 정렬하려 합니다.
예를 들어 다음과 같이 데이터가 주어진다면
data = [[1, 20300104, 100, 80], [2, 20300804, 847, 37], [3, 20300401, 10, 8]]
이 데이터는 다음 표처럼 나타낼 수 있습니다.
codedatemaximumremain
| 1 | 20300104 | 100 | 80 |
| 2 | 20300804 | 847 | 37 |
| 3 | 20300401 | 10 | 8 |
주어진 데이터 중 "제조일이 20300501 이전인 물건들을 현재 수량이 적은 순서"로 정렬해야 한다면 조건에 맞게 가공된 데이터는 다음과 같습니다.
data = [[3,20300401,10,8],[1,20300104,100,80]]
정렬한 데이터들이 담긴 이차원 정수 리스트 data와 어떤 정보를 기준으로 데이터를 뽑아낼지를 의미하는 문자열 ext, 뽑아낼 정보의 기준값을 나타내는 정수 val_ext, 정보를 정렬할 기준이 되는 문자열 sort_by가 주어집니다.
data에서 ext 값이 val_ext보다 작은 데이터만 뽑은 후, sort_by에 해당하는 값을 기준으로 오름차순으로 정렬하여 return 하도록 solution 함수를 완성해 주세요. 단, 조건을 만족하는 데이터는 항상 한 개 이상 존재합니다.
나의 풀이
def solution(data, ext, val_ext, sort_by):
answer = []
data2 = []
dict = {"code" : 0, "date" : 1, "maximum":2, "remain":3}
sort_li = []
for d in data:
if d[dict[ext]] < val_ext:
data2.append(d)
sort_li.append(d[dict[sort_by]])
sorted_li = sorted(sort_li)
for s in sorted_li:
answer.append(data2[sort_li.index(s)])
return answer
딕셔너리형태로 data의 0,1,2,3 인덱스와 데이터 컬럼명을 연결해주었다.
컬럼명을 통해 인덱스를 찾아 data내의 각각의 리스트 d의 ext 값이 val_ext 보다 작은지 비교하여 작으면 data2에 추가하는 방식으로 data2를 만들고,
sort_by를 sort_li에 넣어 sorted한 sorted_li를 기준으로 해당 인덱스의 data2 의 리스트를 answer 리스트에 추가하도록 하였다.
다른사람 풀이 + 개선점
def solution(data, ext, val_ext, sort_by):
answer = []
by = [ "code", "date", "maximum", "remain" ]
for item in data:
if item[by.index(ext)] < val_ext:
answer.append(item)
return sorted(answer, key=lambda x: x[by.index(sort_by)])
이전 다른 문제에서도 쓰였던 sorted(리스트, key = lambda x : 정렬 기준) 을 통해 정렬할 수 있다.
5. 신규 아이디 추천
문제 설명
카카오에 입사한 신입 개발자 네오는 "카카오계정개발팀"에 배치되어, 카카오 서비스에 가입하는 유저들의 아이디를 생성하는 업무를 담당하게 되었습니다. "네오"에게 주어진 첫 업무는 새로 가입하는 유저들이 카카오 아이디 규칙에 맞지 않는 아이디를 입력했을 때, 입력된 아이디와 유사하면서 규칙에 맞는 아이디를 추천해주는 프로그램을 개발하는 것입니다.
다음은 카카오 아이디의 규칙입니다.
- 아이디의 길이는 3자 이상 15자 이하여야 합니다.
- 아이디는 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.) 문자만 사용할 수 있습니다.
- 단, 마침표(.)는 처음과 끝에 사용할 수 없으며 또한 연속으로 사용할 수 없습니다.
"네오"는 다음과 같이 7단계의 순차적인 처리 과정을 통해 신규 유저가 입력한 아이디가 카카오 아이디 규칙에 맞는 지 검사하고 규칙에 맞지 않은 경우 규칙에 맞는 새로운 아이디를 추천해 주려고 합니다.
신규 유저가 입력한 아이디가 new_id 라고 한다면,
1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다.
만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다.
7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
예를 들어, new_id 값이 "...!@BaT#*..y.abcdefghijklm" 라면, 위 7단계를 거치고 나면 new_id는 아래와 같이 변경됩니다.
1단계 대문자 'B'와 'T'가 소문자 'b'와 't'로 바뀌었습니다.
"...!@BaT#*..y.abcdefghijklm" → "...!@bat#*..y.abcdefghijklm"
2단계 '!', '@', '#', '*' 문자가 제거되었습니다.
"...!@bat#*..y.abcdefghijklm" → "...bat..y.abcdefghijklm"
3단계 '...'와 '..' 가 '.'로 바뀌었습니다.
"...bat..y.abcdefghijklm" → ".bat.y.abcdefghijklm"
4단계 아이디의 처음에 위치한 '.'가 제거되었습니다.
".bat.y.abcdefghijklm" → "bat.y.abcdefghijklm"
5단계 아이디가 빈 문자열이 아니므로 변화가 없습니다.
"bat.y.abcdefghijklm" → "bat.y.abcdefghijklm"
6단계 아이디의 길이가 16자 이상이므로, 처음 15자를 제외한 나머지 문자들이 제거되었습니다.
"bat.y.abcdefghijklm" → "bat.y.abcdefghi"
7단계 아이디의 길이가 2자 이하가 아니므로 변화가 없습니다.
"bat.y.abcdefghi" → "bat.y.abcdefghi"
따라서 신규 유저가 입력한 new_id가 "...!@BaT#*..y.abcdefghijklm"일 때, 네오의 프로그램이 추천하는 새로운 아이디는 "bat.y.abcdefghi" 입니다.
나의 풀이
def point(x):
while x[0] == '.' or x[-1] == '.':
if x[0] == '.':
x = x[1:]
else:
x = x[:-1]
return x
def solution(new_id):
char_li = ['.','-','_']
new_id = new_id.lower()
new_id = "".join([n for n in new_id if n.isalpha() or n in char_li or n.isdigit()])
new_id = "".join([new_id[i] for i in range(len(new_id)) if not (new_id[i-1] =='.' and new_id[i] == '.')])
if len(new_id) == 0 :
new_id = "a"
else:
new_id = point(new_id)
if len(new_id) > 15:
new_id = new_id[:15]
new_id = point(new_id)
if len(new_id) < 3:
new_id += new_id[-1]*(3-len(new_id))
return new_id
문제에서 제시한 로직 그대로 풀이하였다.
다른사람 풀이 + 개선점
import re
def solution(new_id):
st = new_id
st = st.lower()
st = re.sub('[^a-z0-9\-_.]', '', st)
st = re.sub('\.+', '.', st)
st = re.sub('^[.]|[.]$', '', st)
st = 'a' if len(st) == 0 else st[:15]
st = re.sub('^[.]|[.]$', '', st)
st = st if len(st) > 2 else st + "".join([st[-1] for i in range(3-len(st))])
return st
정규식을 사용한 풀이이다.
re.sub(pattern, replace, text)
: text 중 pattern에 해당하는 부분을 replace로 대체한다.
'프로그래머스' 카테고리의 다른 글
| [프로그래머스] Python Lv.1 다트 게임 외 5문제 (1) | 2024.11.07 |
|---|---|
| [프로그래머스] Python Lv.1 2016년 외 5문제 (6) | 2024.11.05 |
| [프로그래머스] Python Lv.1 최대공약수와 최소공배수 외 5문제 (2) | 2024.10.30 |
| Python Lv1. k번째 수 외 5문제 (1) | 2024.10.02 |
| [프로그래머스] Python Lv.1 부족한 금액 계산하기 외 5문제 (4) | 2024.09.30 |