데이터 전처리 - 판다스(Pandas) 사용 및 csv 파일 데이터 처리

판다스(Pandas)
- 행렬 데이터를 처리하기 위한 다양한 함수를 지원하는 라이브러리
- 파일 읽기, 저장, 행렬데이터 처리, 기본 시각화 등 지원
- 데이터 전처리 과정에서 주로 사용
<데이터 분석과정>
데이터 수집 > 데이터 전처리 > 데이터 가공(필요시 전처리)
> 데이터 분석 탐색/시각화(필요시 전처리) > 필요시 모델 훈련(머신러닝 or 딥러닝)
> 웹서비스 또는 분석보고서
* 일반적으로 책에서는 : 데이터 수집 > 전처리 > 분석 > 시각화 로 설명되고 있음
* 분석과정은 회사에 따라 다름
pip list 통해 설치되어있는 라이브러리 확인 가능
conda list > 아나콘다 설치시 pip list와 동일하게 사용 가능
<데이터 수집 시 확인 사항>
- 날짜 확인 : 기준일로 사용
- 범주형 데이터 확인 : 예로 남자 또는 여자와 같은 데이터
데이터 전처리
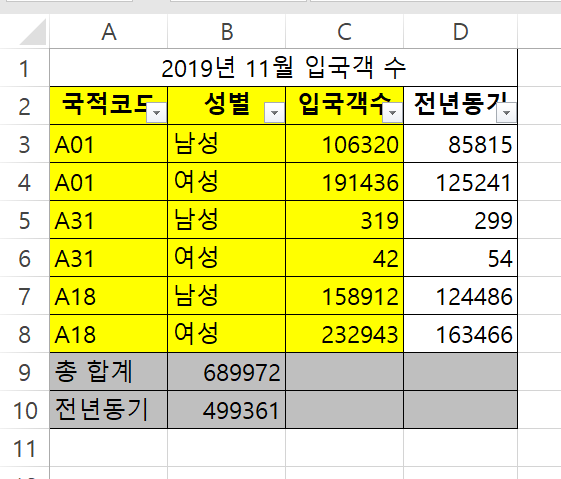
데이터 읽어들이기
file_path = "./files/sample_1.xlsx"
# file_path = "C:\Users\user\gj202311\04_데이터_처리_시각화\01_데이터_전처리기초\files" # 절대 경로
▶ 먼저 파일 경로를 절대 경로 또는 상대 경로로 지정해준다. 파일의 위치를 변경할 수 있으므로 상대경로로 지정해주는 것이 좋다.
sample_1 = pd.read_excel(file_path, header = 1 ,skipfooter = 2, usecols = "A:C")
▶ 파일 데이터 추출하기
- 첫번째 : 파일 지정(위치 포함)
- 두번째 : 컬럼명으로 사용할 행의 위치(디폴트 0)
- 세번째 : 행의 가장 밑에서 포함하지 않을 행의 개수(디폴트 0)
- 네번째 : 가지고 올 열의 범위(A부터 C까지의 열) -> 디폴트 데이터가 있는 모든 열
sample_1.info()
▶ 데이터프레임 정보 확인하기
- DataFrame 타입 : 행렬을 저장 관리하는 타입
- info() 함수는 데이터의 결측치(non,null) 데이터 확인 가능 (중요)
- RangeIndex : 전체 행(row)의 개수
- 전체 행의 개수와 각 컬럼의 개수(Non-Null의 개수)가 안맞으면 -> 결측데이터가 존재한다는 의미
sample_1
▶ 데이터프레임 출력
- 데이터 행/열이 많은 경우 -> 기본 상위 5개 , 하위 5개를 추출해서 보여줌
- 데이터 행/열의 개수가 작으면 모두 보여줌
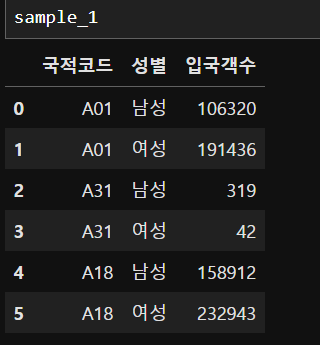
sample_1.head()
sample_1.head(1)
sample_1.tail()
sample_1.tail(1)
▶ head(개수) : 상위 데이터 조회 / tail(개수) : 하위 데이터 조회


sample_1.describe()
▶ 기초통계 데이터
- count : 데이터 행의 개수
- mean : 데이터 평균
- std : 표준편차
- min : 최소값
- max : 최대값
- 25% , 50% , 75% : 4분위수 데이터 → 4분위수 데이터를 이용해서 이상치(이상한) 데이터 확인한다.
- 숫자값을 가지는 컬럼에 대해서만 확인
데이터 조회하기
### 국적코드 데이터 조회하기
sample_1['국적코드']

▶ 이때의 데이터 타입은 Series
Series : 튜플과 모양()이 같다.(사용법도 동일함)
{"국적코드" : ( 데이터, 데이터,...)}
sample_1[["성별"]]
▶ 이때의 데이터 타입은 DataFrame
sample_1[["국적코드","성별"]] 이런식으로 국적코드와 성별의 데이터만 조회할 수 있다.
컬럼 추가 하기
### 2019-11 값 추가하기
sample_1["기준년월"] = "2019-11"
데이터 필터링하기
### 성별 중에 여성인 데이터만 추출하기
condition = sample_1["성별"] == "여성"
sample_1[condition]
# 반대의 경우 남성 데이터만 추출하고자 할때 조건
sample_1[condition == False]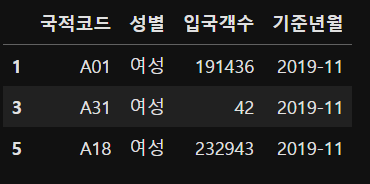
데이터 주소 전달/메모리 복제하기
sample_2 = sample_1
▶ 객체 주소 전달 방식
둘다 같은 곳을 바라본다.
하나가 변경되면 다른 하나도 변경됨
sample_2 = sample_1.copy()
▶ copy() : 메모리 복제방식(신규로 동일하게 생성됨)
하나가 변경되어도 다른 하나는 영향을 받지 않음
[ 실습 ]
공공데이터 포털 data.go.kr 의 < 한국전력거래소 시간별 전력수요량 > 데이터 사용
csv 파일로 다운로드 받아서 사용
### 데이터 불러들이기
# 데이터 프레임 변수명 : df
import pandas as pd
file_path = "./01_data/한국전력거래소_시간별 전력수요량_20211231.csv"
df = pd.read_csv(file_path , encoding = 'euc-kr')
▶ 한글 읽기 위해 encoding 필요
이후 info() , describe() 통해 결측치와 이상치 확인 → 둘 다 없음
3개의 열(년도 , 시간 , 전력량) 을 가지는 데이터 프레임 생성하기
### 컬럼명의 시간을 데이터화하기
# - 컬럼명 추출하기
col_list = df.columns
col_list
result_df = pd.DataFrame(columns = ["년도","시간","전력량"])
result_df
### 데이터프레임에 데이터 행단위 추가하기
for index, row in df.iterrows():
# 년도 데이터
ymd = row[col_list[0]]
# 시간과 전력량 데이터
data = row[col_list[1:]]
# 시간과 전력량을 각각 추출하여 데이터프레임에 넣기
# 넣을 값 : 날짜, 시간 , 전력량
for time, value in data.items():
# 행단위로 데이터 프레임에 추가하기 위해서 추가할 행을 데이터프레임 생성
df_temp = pd.DataFrame({"년도":[ymd],"시간":[time],"전력량":[value]})
# 데이터프레임에 행단위로 추가하기
# - concat() : 데이터 프레임과 데이터프레임을 행단위(axis = 0) 또는 컬럼단위(axis = 1)로 추가할 때 사용
# ignoere_index = True : 행이 추가될 때 행 인덱스 번호를 자동 증가 시키기(default = false)
result_df = pd.concat([result_df,df_temp], axis = 0 , ignore_index = True)
# 최종 결과 출력하기
result_df

정제된 데이터 파일로 저장하기
### 저장할 경로 지정
save_path = "./01_data/new_data.csv"
result_df.to_csv(save_path)

▶ 저장해야 나중에 사용할때 용이함