[데이터실습] (1) - 한 건의 데이터 샘플링
이제까지 배운 내용을 토대로 데이터를 받아와서 처리하는 실습을 진행하였다.
데이터는 국가 교통 데이터 오픈마켓에서 <포항시 BIS 교통카드 사용내역 데이터 수집> 데이터를 사용하였다.
80개의 파일을 받아서 이를 하나의 데이터 파일로 합친 후에 진행해야한다.
따라서 한 건의 데이터 샘플링을 실행하고 이를 80개의 파일에 적용하는 순서로 수행하였다.
한 건의 데이터 샘플링
ⓛ 라이브러리 정의 및 데이터 읽어들이기
# 라이브러리 정의
import pandas as pd
# 0번 파일의 csv 데이터 읽어들이기
# 데이터 프레임 이름 : df_bus_card_org
# 파일 경로 지정
file_path = "./01_data/org/trfcard(0)/trfcard.csv"
df_bus_card_org = pd.read_csv(file_path)
df_bus_card_org.head(1)
② 결측치 / 이상치 확인
# 결측치 확인
df_bus_card_org.info()
# 이상치 확인
df_bus_card_org.describe()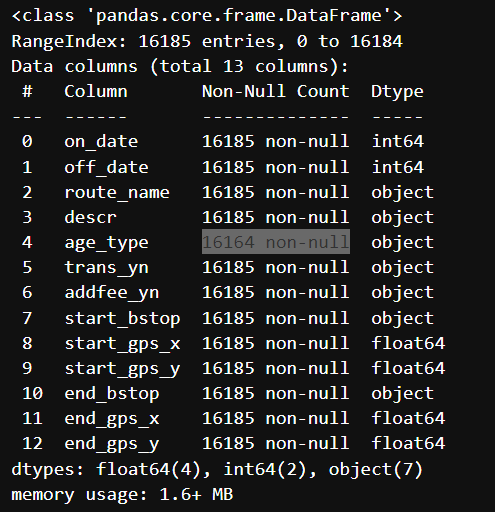
▶ 결측치가 있는 것을 확인할 수 있다. 이상치는 없음
③ 영문 컬럼명을 한글 컬럼명으로 바꾸기
1) 메타 정의서에서 영문명 ,한글명 컬럼 읽어 들이기
### 메타정의서의 영문명, 한글명 컬럼 읽어들이기
# 데이터 프레임 이름 : df_bus_card_col_org
file_path = "./01_data/org/trfcard(0)/trfcard_columns.xlsx"
df_bus_card_col_org = pd.read_excel(file_path,header = 2 , usecols = "B:C")
df_bus_card_col_org
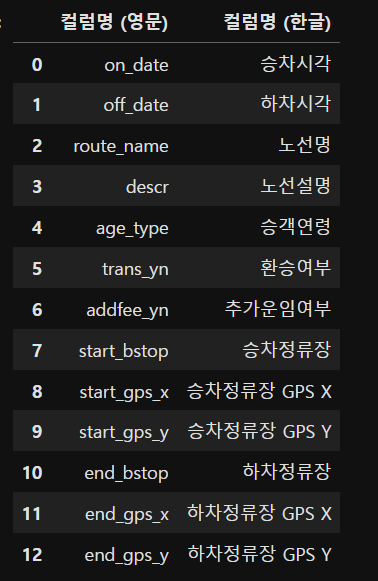
2 ) 영문명을 key로 한글명을 value로 하는 딕셔너리 만들기
이때 사용하면 좋은 함수가 있다 바로 iloc와 loc 인데 아래 예시로 설명하겠다.
print(df_bus_card_col_org.iloc[0,0])
print(df_bus_card_col_org.iloc[0,1])
print(df_bus_card_col_org.loc[0,"컬럼명 (영문)"])
print(df_bus_card_col_org.loc[0,"컬럼명 (한글)"])
on_date
승차시각
on_date
승차시각
▶ iloc[ 행번호 , 열번호 ] : 0번째 행의 0번째 컬럼 , 0번째 행의 1번째 컬럼 인덱스 번호를 통해 값을 가져올 수 있음
loc[ 행값 , 열값] : 눈에 보이는 인덱스 값을 이용하는 방식
### df_bus_card_col_org 데이터 프레임을 딕셔너리로 변환
# 딕셔너리 변수명 : df_bus_card_col_new_dict
# 영문명은 key 한글명은 value
df_bus_card_col_new_dict = {}
for i in range(13):
df_bus_card_col_new_dict[df_bus_card_col_org.iloc[i,0]] = df_bus_card_col_org.iloc[i,1]
df_bus_card_col_new_dict
# zip 사용 구문
# for k,v in zip(df_bus_card_col_org.iloc[:,0],df_bus_card_col_org.iloc[:,1]):
# df_bus_card_col_new_dict[k] = v
{'on_date': '승차시각', 'off_date': '하차시각', 'route_name': '노선명', 'descr': '노선설명', 'age_type': '승객연령', 'trans_yn': '환승여부', 'addfee_yn': '추가운임여부', 'start_bstop': '승차정류장', 'start_gps_x': '승차정류장 GPS X', 'start_gps_y': '승차정류장 GPS Y', 'end_bstop': '하차정류장', 'end_gps_x': '하차정류장 GPS X', 'end_gps_y': '하차정류장 GPS Y'}
▶ for문을 통해 딕셔너리를 만들었다
3) 컬럼명 변경하기
### 컬럼명 변경하기
# df_bus_card_org.rename(columns = df_bus_card_col_new_dict)
# inplace = True : 변경사항을 메모리에 반영하기
df_bus_card_org.rename(columns = df_bus_card_col_new_dict,inplace = True)
▶ inplace = True를 적어야 실제 메모리에 반영됨 그 전에는 실제 데이터에 반영되지 않음


분석 주제
- 대주제 : 포항시 버스 이용량 분석
- 소주제 :
(버스 이용량 분석)
* 기준월 및 기준일자별 버스 이용량 분석 비교
* 기준일 및 시간대별 버스 이용량 분석 비교
* 기준시간 및 시간(분)별 버스 이용량 분석 비교
(버스 내 체류시간 분석)
* 기준월 및 기준일자별 버스 체류시간 분석 비교
* 기준일 및 시간대별 버스 체류시간 분석 비교
* 기준시간 및 시간(분)별 버스 체류시간 분석 비교
* 승하차정류장 구간별 버스 내 체류시간
- 체류시간(분) 상위 30건 분석 비교
데이터 가공하기
우선 체류시간 관련 주제를 위한 데이터를 가공하였다.
① 승차시각과 하차시간 데이터 타입을 문자열로 변환하기
# 데이터 프레임 복제
df_bus_card_kor = df_bus_card_org.copy()
# astype() : 데이터 형변환 함수
# inplace 사용할 수 없어서 자기 자신에게 넣는 방법 사용
df_bus_card_kor = df_bus_card_kor.astype({"승차시각":"str","하차시각":"str"})
df_bus_card_kor.info()
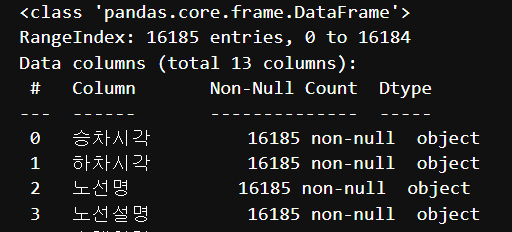
② 분석에 필요한 컬럼 추출하기
df_bus_card = df_bus_card_kor[["승차시각","하차시각","승객연령","환승여부","추가운임여부","승차정류장","하차정류장"]].copy()
③ 승차 시각과 하차시각의 데이터 타입을 날짜 타입으로 변경하기
문자열로 바꾼뒤에 날짜 타입으로 바꿀 수 있다. 따라서 앞에서 문자열로 형 변환 한 것!!
df_bus_card["승차시각"] = pd.to_datetime(df_bus_card_kor.loc[:,"승차시각"])
df_bus_card["하차시각"] = pd.to_datetime(df_bus_card_kor.loc[:,"하차시각"])
▶ datetime64로 바뀐 것을 확인 할 수 있다. pd.to_datetime()을 사용한다.
④ 버스 내 체류시간(분단위) 컬럼 만들기
df_bus_card["버스내체류시간(분)"] = round((df_bus_card["하차시각"]- \
df_bus_card["승차시각"]).dt.total_seconds() / 60,2)
# 컬럼명 없는 데이터 형태 Series 형태로 나옴
# \ 역슬래시는 한 문장으로 인식하는 줄바꿈 기호
# dt : datetime
▶ round( (하차시간 - 승차시간) .dt. total_seconds() / 60 ,2 )
체류시간을 초단위로 바꾸어 60으로 나눠 분단위로 만든 후 소수점 두번째 자리까지 나오도록 한다.
⑤ 기준년도 , 기준월 , 기준일 , 기준시간 , 기준시간(분) 컬럼 생성하기
# 기준년도
df_bus_card["기준년도"] = df_bus_card["승차시각"].dt.year
# 기준월
df_bus_card["기준월"] = df_bus_card["승차시각"].dt.month
# 기준일
df_bus_card["기준일"] = df_bus_card["승차시각"].dt.day
# 기준 시간
df_bus_card["기준시간"] = df_bus_card["승차시각"].dt.hour
# 기준 시간(분)
df_bus_card["기준시간(분)"] = df_bus_card["승차시각"].dt.minute
