[웹크롤링] - 다음 영화 사이트 웹크롤링
<다음 영화 사이트 웹크롤링>
- URL : https://movie.daum.net
- 다음영화 > 랭킹 > 박스오피스 > 월간 위치의 데이터 수집
- 수집데이터 : 영화제목, 평점, 댓글
- 생성할 데이터 : 긍정/부정
<웹크롤링 라이브러리>
- 정적 웹크롤링 : BeautifulSoup
: 하나의 페이지에 보이는 부분만 수집할 때 사용
- 동적 웹크롤링 : selenium
: 클릭과 같은 이벤트 등 페이지 전환을 하면서 수집할 때 사용
동적 웹크롤링으로 다음영화 사이트 웹크롤링을 해볼 것이다.
영화 10건에 대한 평점과 리뷰를 웹크롤링하여 평점 데이터를 통해 긍정/부정 데이터 생성
① 라이브러리 설치
pip install selenium - 설치 안되어있으면 명령프롬프트에서 설치
# 설치필요 : pip install selenium
# 동적 웹페이지 처리를 위한 라이브러리
from selenium import webdriver
# 웹페이지 내에 데이터 추출을 위한 라이브러리
from selenium.webdriver.common.by import By
# 시간 라이브러리 추가
import time
② 웹페이지와 연결
### 크롬 브라우저 띄우기
# 브라우저 컨트롤
driver = webdriver.Chrome()
# url을 이용하여 페이지 접근
# get() : 페이지에 접근 후 해당 html 코드 읽어 들이기
# driver 객체가 모든 정보를 가지고 있음
driver.get("https://movie.daum.net/ranking/boxoffice/monthly")
③ 영화 제목이 있는 부분의 html 태그 경로(패스) 추출하기
방법 :
크롬 브라우저 > F12(개발자 모드) > 영화 제목 마우스 우클릭 > [검사]클릭 > a태그에 마우스 위치 후 우클릭 > Copy > Copy Selector클릭
해당 제목의 위치 저장됨
# a태그의 위치 경로
movie_path = "#mainContent > div > div.box_boxoffice > ol > li > div > div.thumb_cont > strong > a"
# 현재 크롬브라우저에 보이는 영화제목 모두 추출하기
movie_elements = driver.find_elements(By.CSS_SELECTOR, movie_path)
print(f"movie_elements Length = {len(movie_elements)}")
print(f"title[0] =>> {movie_elements[0].text}")
print(f"movie_elements(제목) = {movie_elements}")
▶ find_element() : 한건 조회, find_elements() : 여러건 조회(리스트타입으로 변환)
By_CSS_SELECTOR : CSS 스타일 경로를 인식할 수 있도록 지정
태그 안의 제목을 출력하기 위해 해당 인덱스.text 해줌.
웹크롤링 처리가 모두 완료되면 driver 종료해야 함 (중요)
driver.quit()
예외가 있을 수 있기때문에 try except를 통한 예외처리가 필요함
try :
driver = webdriver.Chrome()
driver.get("https://movie.daum.net/ranking/boxoffice/monthly")
movie_path = "#mainContent > div > div.box_boxoffice > ol > li > div > div.thumb_cont > strong > a"
movie_elements = driver.find_elements(By.CSS_SELECTOR, movie_path)
print(f"movie_elements Length = {len(movie_elements)}")
print(f"title[0] =>> {movie_elements[0].text}")
print(f"movie_elements(제목) = {movie_elements}")
except Exception as e :
print(e)
driver.quit()
finally :
driver.quit()예외가 있어도 없어도 무조건 driver 종료하게 하는 구문
④ 영화 상세정보에서 평점 탭으로 이동
페이지 로딩 시간 벌어주는것 중요!
# [평점] 탭 클릭 이벤트 발생시키기
tab_score_path = "#mainContent > div > div.box_detailinfo > div.tabmenu_wrap > ul > li:nth-child(4) > a"
# a태그 정보 가지고 오기
tab_score_element = driver.find_element(By.CSS_SELECTOR,tab_score_path)
# [평점] 탭, 즉 a태그 클릭 이벤트 발생시키기
tab_score_element.click()
# [평점] 페이지로 접근했다라는 정보를 받아오기
tab_score_handle = driver.window_handles[-1]
# 새로 열린 페이지로 전환하기
driver.switch_to.window(tab_score_handle)
# 페이지 로딩 시간 벌어주기
time.sleep(1)
⑤ 평점 / 리뷰 데이터 추출하기
# 모든 평점 데이터 추출하기
score_path = "#alex-area > div > div > div > div.cmt_box > ul.list_comment div.ratings"
score_lists = driver.find_elements(By.CSS_SELECTOR,score_path)
# 모든 리뷰 데이터 추출하기
comment_path = "#alex-area > div > div > div > div.cmt_box > ul.list_comment p.desc_txt"
comment_lists = driver.find_elements(By.CSS_SELECTOR,comment_path)
▶ ul.list_comment 안의 모든 평점과 리뷰만 가져오기 위해 div.ratings / p.desc_txt 로 경로 지정
⑥ 평점을 이용하여 긍정/부정 값 생성하기
긍정/부정 기준
- 긍정 : 평점이 8 이상인 경우로 긍정값은 1
- 부정 : 평점이 4이하인 경우로 부정값은 0 사용
- 기타 : 나머지 기타값은 2 사용
for j in range(len(score_lists)):
score = score_lists[j].text.strip()
comment = comment_lists[j].text.strip().replace("\n","")
# 평점을 이용해서 긍정/부정 데이터 생성
label = 0
if int(score) >= 8:
label = 1
elif int(score) <= 4:
label = 0
else:
label = 2
# 각 제목별 평점/긍정부정값/리뷰 확인
print(f"{title} \t{score} \t 긍정부정값: {label}\t{comment}\n")
⑦ 상세페이지(평점)에서 영화 월간 박스오피스로 다시 되돌리기
다시 메인페이지로 돌아가야 각 영화 제목으로 다시 for문이 돌아가면서 각각의 평점/리뷰 데이터를 추출할 수 있다.
# 영화 한편에 대한 정보 수집이 끝나면 다시 메인으로 이동
# execute_script() : 자바스크립트 문법 처리 함수
driver.execute_script("window.history.go(-2)")
time.sleep(1)
⑧ 수집데이터 txt 파일로 저장시키기
f = open("./data/movie_reviews.txt","w",encoding= "UTF-8")
# 데이터 추출 후
# 파일에 쓰기
f.write(f"{title}\t{score}\t{comment}\t{label}\n")
# driver 종료 전
f.close()
실행하면 txt 파일로 저장된 것을 확인할 수 있다.
⑨ 평점 더보기 클릭하여 전체 평점 데이터 가져오기
평점 첫 화면에는 10개의 평점과 리뷰만 나온다.
이때 평점 더보기를 클릭하면 10개의 평점이 더 나오는데
전체 평점 데이터를 가져오기 위해 평점 더보기를 전체 다 클릭하도록 한 후에 전체 평점 데이터를 가져오도록 한다.
아래는 평점 더보기를 전체 다 클릭하도록 하는 구문이다.
more_view_cnt = 0
# 모두 펼치기(더보기) 수행
while True:
try:
more_view_path = "#alex-area > div > div > div > div.cmt_box > div.alex_more > button"
more_view_element = driver.find_element(By.CSS_SELECTOR,more_view_path)
more_view_element.click()
more_view_handle = driver.window_handles[-1]
driver.switch_to.window(more_view_handle)
time.sleep(1)
# 임시로 2번만 반복처리 후 break 처리
if more_view_cnt == 2:
break
# 더보기 클릭 횟수 확인을 위해 1씩 증가
more_view_cnt += 1
except Exception as e:
# 더이상 더보기 버튼이 보이지 않으면 오류 발생
# 오류 발생 시점이 더보기 버튼이 끝나는 시점
break
# 더보기 클릭횟수 확인하기
print(f"더보기 클릭 횟수 : {more_view_cnt}")
이때 평점중 리뷰가 적히지 않은 경우도 있어서 list index out of range 라는 오류가 발생하였다.
그래서 평점을 불러들이는 for문을 수정하였다.
for_cnt = 0
if len(score_lists) < len(comment_lists) :
for_cnt = len(score_lists)
elif len(score_lists) > len(comment_lists):
for_cnt = len(comment_lists)
else:
for_cnt = len(score_lists)
for j in range(for_cnt):
score = score_lists[j].text.strip()
comment = comment_lists[j].text.strip().replace("\n","")for_cnt를 사용해서 평점과 리뷰의 리스트들 중 값이 없는 경우때문에 리스트의 길이가 적은 리스트를 기준으로
for문을 돌린다.
[최종 코드]
try :
driver = webdriver.Chrome()
driver.get("https://movie.daum.net/ranking/boxoffice/monthly")
movie_path = "#mainContent > div > div.box_boxoffice > ol > li > div > div.thumb_cont > strong > a"
movie_elements = driver.find_elements(By.CSS_SELECTOR, movie_path)
#-----------------------------
# 수집데이터 txt 파일로 저장시키기
f = open("./data/movie_reviews.txt","w",encoding= "UTF-8")
#-------------------------------
# 영화제목 10개에 대해 for문 수행
for i in range(10):
title = movie_elements[i].text.strip()
print(f"title[{i}] =>> {title}")
# 제목을 클릭시켜서 상세페이지로 이동하기
# 마우스로 제목을 클릭하는 행위와 동일한 코드
# click() 이벤트 발
movie_elements[i].click()
# 상세페이지로 접근했다라는 정보를 받아오기
# 실제 상세페이지에 접근
# window_handles : 페이지가 열릴때마다 리스트 타입으로 윈도우 정보를 순서대로 가지고 있는 객체(-1은 마지막에 접근한 페이지를 의미함)
movie_handle = driver.window_handles[-1]
# 새로 열린 페이지로 전환하기
driver.switch_to.window(movie_handle)
# 페이지 로딩 및 코드 읽어들이는 시간 벌어주기 (1초)
time.sleep(1)
#------------------------------
# [평점] 탭 클릭 이벤트 발생시키기
tab_score_path = "#mainContent > div > div.box_detailinfo > div.tabmenu_wrap > ul > li:nth-child(4) > a"
# a태그 정보 가지고 오기
tab_score_element = driver.find_element(By.CSS_SELECTOR,tab_score_path)
# [평점] 탭, 즉 a태그 클릭 이벤트 발생시키기
tab_score_element.click()
# [평점] 페이지로 접근했다라는 정보를 받아오기
tab_score_handle = driver.window_handles[-1]
# 새로 열린 페이지로 전환하기
driver.switch_to.window(tab_score_handle)
# 페이지 로딩 시간 벌어주기
time.sleep(1)
#----------------------------
# [평점] 더보기 버튼을 클릭하여 모두 펼치기
# 펼친 개수 확인 변수
more_view_cnt = 0
# 모두 펼치기(더보기) 수행
while True:
try:
more_view_path = "#alex-area > div > div > div > div.cmt_box > div.alex_more > button"
more_view_element = driver.find_element(By.CSS_SELECTOR,more_view_path)
more_view_element.click()
more_view_handle = driver.window_handles[-1]
driver.switch_to.window(more_view_handle)
time.sleep(1)
# 임시로 2번만 반복처리 후 break 처리
# if more_view_cnt == 2:
# break
# 더보기 클릭 횟수 확인을 위해 1씩 증가
more_view_cnt += 1
except Exception as e:
# 더이상 더보기 버튼이 보이지 않으면 오류 발생
# 오류 발생 시점이 더보기 버튼이 끝나는 시점
break
# 더보기 클릭횟수 확인하기
print(f"더보기 클릭 횟수 : {more_view_cnt}")
#------------------------------
# 모든 평점 데이터 추출하기
score_path = "#alex-area > div > div > div > div.cmt_box > ul.list_comment div.ratings"
score_lists = driver.find_elements(By.CSS_SELECTOR,score_path)
# 모든 리뷰 데이터 추출하기
comment_path = "#alex-area > div > div > div > div.cmt_box > ul.list_comment p.desc_txt"
comment_lists = driver.find_elements(By.CSS_SELECTOR,comment_path)
#-----------------------------
# 평점, 리뷰 추출하기
# 평점을 이용하여 긍정/부정 값 생성하기
# 평점 또는 리뷰 데이터가 없을 수 있기에
# 두개 리스트의 갯수 중 작은 값을 사용
# 평점 또는 리뷰가 없으면 수집에서 제외
for_cnt = 0
if len(score_lists) < len(comment_lists) :
for_cnt = len(score_lists)
elif len(score_lists) > len(comment_lists):
for_cnt = len(comment_lists)
else:
for_cnt = len(score_lists)
for j in range(for_cnt):
score = score_lists[j].text.strip()
comment = comment_lists[j].text.strip().replace("\n","")
# 평점을 이용해서 긍정/부정 데이터 생성
# 긍정 : 평점이 8 이상인 경우로 긍정값은 1
# 부정 : 평점이 4이하인 경우로 부정값은 0 사용
# 기타 : 나머지 기타값은 2 사용
label = 0
if int(score) >= 8:
label = 1
elif int(score) <= 4:
label = 0
else:
label = 2
# 각 제목별 평점/긍정부정값/리뷰 확인
print(f"{title} \t{score} \t 긍정부정값: {label}\t{comment}\n")
# 파일에 쓰기
f.write(f"{title}\t{score}\t{comment}\t{label}\n")
#-----------------------
# 영화 한편에 대한 정보 수집이 끝나면 다시 메인으로 이동
# execute_script() : 자바스크립트 문법 처리 함수
driver.execute_script("window.history.go(-2)")
time.sleep(1)
except Exception as e :
print(e)
# 파일 자원 닫기
f.close()
driver.quit()
finally :
# 파일 자원 닫기
f.close()
driver.quit()
현재 월간 박스오피스 10위 안의 영화에 대한 평점과 리뷰 데이터를 txt 파일에 저장함.
데이터 전처리 및 시각화
① 라이브러리 정의 및 외부 파일 읽어들이기
import pandas as pd
file_path = "./data/movie_reviews.txt"
df_org = pd.read_csv(file_path,
delimiter="\t",
names = ["title","score","comment","label"])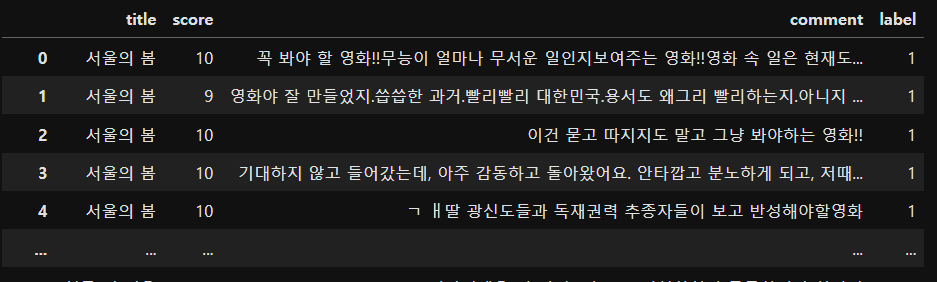
▶ 데이터 프레임에 저장된 것을 확인할 수 있음.
② 평점(score) / 긍정/부정값(label) 현황 데이터 확인하기
# 평점(score) 현황 데이터 확인
df_org["score"].value_counts()
# 긍정/부정 현황 데이터 확인
df_org["label"].value_counts()


③ 중복 데이터 확인 후 제거하기
# 중복 데이터 확인하기
# keep=False : 중복된 모든행 체크(중복이 있으면 True, 없으면 False)
# df_org[df_org.duplicated(keep=False) == True]
df_del = df_org[df_org.duplicated() == True]총 40개의 중복 데이터가 있음을 확인함
중복 데이터 제거하는 코드를 작성하였다.
# 중복 제거하기
df_new = df_org.drop_duplicates()
len(df_new)
총 4073개의 데이터 중 40개의 데이터가 제거되고 4033개의 데이터가 남음
데이터 탐색하기
① 영화 제목만 출력하기
df_new["title"].unique()
array(['서울의 봄', '그대들은 어떻게 살 것인가', '더 마블스', '프레디의 피자가게', '소년들', '30일', '톡 투 미', '헝거게임: 노래하는 새와 뱀의 발라드', '뉴 노멀', '싱글 인 서울'], dtype=object)
② 영화 제목별 리뷰개수 현황 확인하기
df_new["title"].value_counts()
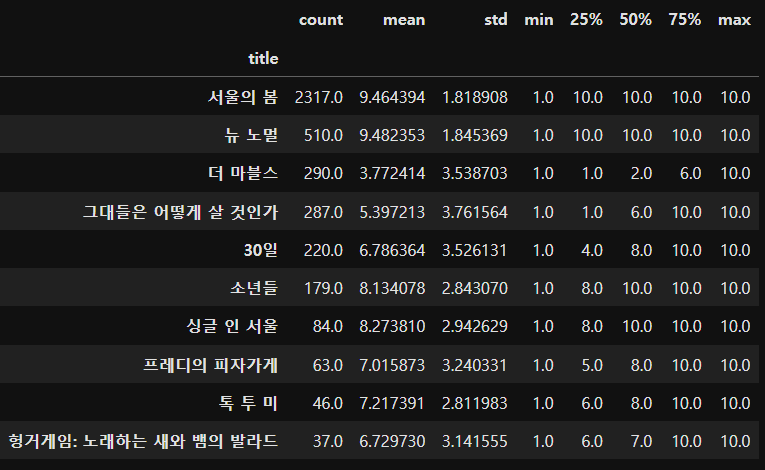
title 서울의 봄 2317 뉴 노멀 510 더 마블스 290 그대들은 어떻게 살 것인가 287 30일 220 소년들 179 싱글 인 서울 84 프레디의 피자가게 63 톡 투 미 46 헝거게임: 노래하는 새와 뱀의 발라드 37 Name: count, dtype: int64
③ 각 영화별 평점 기초통계 확인하기
### 각 영화별 평점 기초통계 확인하기
# 영화 제목별 평점에 대한 그룹 집계하기
movie_info = df_new.groupby("title")["score"].describe()
# 기초통계 행단위 데이터 내림차순 정렬하기
movie_info = movie_info.sort_values(by=["count"],axis = 0, ascending = False)
movie_info왼쪽 사진은 그룹 집계만 했을 때, 오른쪽 사진은 데이터 내림차순 정렬했을 때이다.
제일 높은 count 값을 가지는 서울의 봄이 제일 위에 있는 것을 확인할 수 있다.

데이터 시각화
라이브러리 정의
matplotlib 라이브러리 사용
한글 폰트, 마이너스 기호 표시 설정
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rc("font",family = "Malgun Gothic")
plt.rcParams["axes.unicode_minus"] = False
영화별 평점평균
① 데이터 추출
# 평점 평균 계산을 위해 사용
import numpy as np
# 영화 제목을 리스트 타입으로 받아오기
movie_title = df_new["title"].unique().tolist()
# 영화별 평점 평균 추출하기
# 평점평균값을 저장할 딕셔너리 변수 선언
avg_score = {}
for m_title in movie_title:
# 평점 평균 계산
avg = df_new[df_new["title"] == m_title]["score"].mean()
# 딕셔너리에 넣기
# key는 제목 , value는 평점평균값
avg_score[m_title] = avg
print(f"딕셔너리 최종값 : {avg_score}")
딕셔너리 최종값 : {'서울의 봄': 9.464393612429866, '그대들은 어떻게 살 것인가': 5.397212543554007, '더 마블스': 3.7724137931034485, '프레디의 피자가게': 7.015873015873016, '소년들': 8.134078212290502, '30일': 6.786363636363636, '톡 투 미': 7.217391304347826, '헝거게임: 노래하는 새와 뱀의 발라드': 6.72972972972973, '뉴 노멀': 9.48235294117647, '싱글 인 서울': 8.273809523809524}
▶ array() : numpy 에서 사용하는 배열(파이썬의 리스트와 동일),
단 , 하나의 타입만 저장 가능함
이외 사용법은 파이썬의 리스트와 동일
unique() : numpy의 배열(array) 타입으로 반환함
tolist() : list 타입으로 변환하는 함수
② 막대 그래프 출력
영화별 평점평균이 가장 큰 영화는 orange 색으로 나머지는 lightgrey 색으로 표현
plt.figure(figsize=(10,5))
plt.title("영화별 평점 평균" , fontsize = 17 , fontweight = "bold")
# 각 영화별 평점평균 막대그래프 그리기
for k,v in avg_score.items():
# 컬러값 지정하기
# array_str() : 문자열로 변환하는 함수
# where() : 파이썬에서 if문과 동일한 조건문
# where(조건,참,거짓) : 조건이 참이면 첫번째 값, 거짓이면 두번째 값 처리
color = np.array_str(np.where(v==max(avg_score.values()),"orange","lightgrey"))
# 막대 그래프 그리기
plt.bar(k,v,color = color)
# 막대그래프 상단에 평점평균 텍스트 표시하기
# "%.2f"%v : 표시할 값(소숫점 2자리까지 표현)
plt.text(k,v,"%.2f"%v,horizontalalignment = "center",
verticalalignment = "bottom")
# x축과 y축 제목 넣기
plt.xlabel("영화제목", fontweight = "bold")
plt.ylabel("평점 평균", fontweight = "bold")
plt.xticks(rotation = 75)
# 그래프를 이미지로 저장시키기
plt.savefig("./img/영화별평점평균막대그래프.png")
plt.show()
각 영화별 평점평균
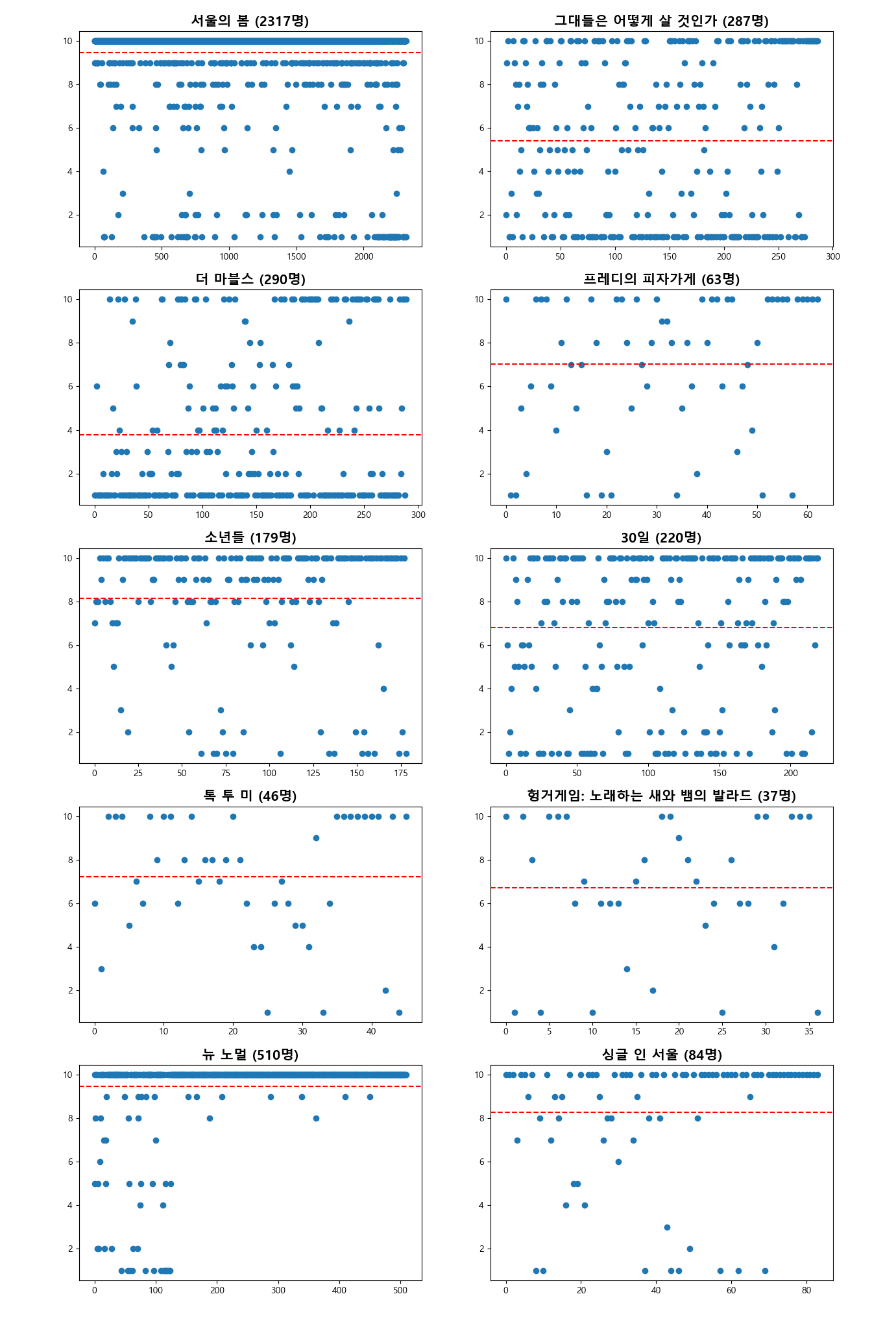
점(분포) 그래프 생성
subplot : 하나의 큰 그래프 안에 10개의 그래프를 넣어서 표현
subplots(행개수, 열개수 , 전체 그래프 크기)
10 개의 영화를 대상으로 만들기 때문에 5행 2열의 subplot을 생성하여 구현한다.
# fig : 큰 그래프 정보
# axs : 5행 2열의 내부 그래프 공간 정보
fig, axs = plt.subplots(5,2,figsize=(15,25))
# 여러개의 그래프를 for문을 이용해서 표현하고자 할때 아래 먼저 수행
# flatten() : 틀 정렬하기 -> 5행 2열의 틀을 정렬해 놓기
axs = axs.flatten()
# 각 그래프를 행렬 공간의 subplot에 넣기
for title, avg , ax in zip(avg_score.keys(),avg_score.values(),axs):
# x축에는 영화 리뷰 개수 , y축에는 평점 평균
# 리뷰 개수 추출하기
num_reviews = len(df_new[df_new["title"] == title])
# arange(num) : 0부터 num까지의 값을 순차적으로 만들기
# 범주형 데이터로 만들기 위함
x = np.arange(num_reviews)
# y축에는 평점 추가
y = df_new[df_new["title"] == title]["score"]
# 각 그래프에 제목 넣기
subtitle = f"{title} ({num_reviews}명)"
ax.set_title(subtitle, fontsize = 15, fontweight = "bold")
# 점 그래프 그리기
# "o" : 점으로 표현하는 마커 기호
ax.plot(x,y,"o")
# 각 영화별 평점평균을 빨간색 점선으로 표시하기
# axhline() : 각 subplot 공간에 수평선 그리기
ax.axhline(avg, color = "red",linestyle = "--")
plt.show()