
퍼셉트론 : 분류에만 사용 가능
일반적으로 딥러닝에서는 분류를 한다
퍼셉트론 잘 쓰지는 않음
< 퍼셉트론(Perceptron) >
- 인공신경망의 한 종류
- 주로 이진분류 또는 다중분류에 사용되는 초기 인공신경망 모델
- 종속변수가 연속형인 회귀에서는 사용되지 않음(분류에서만 사용)
- 퍼셉트론에는 단층 퍼셉트론과 다층 퍼셉트론이 있음
- 주로 다층퍼셉트론이 성능이 좋음
< 단층 퍼셉트론(Single-Layer perceptron, SLP) >
- 입력층과 출력층으로만 구분되어있음
- 주로 이진분류에 사용됨(성능이 낮은경우, 다층 퍼셉트론으로 사용)
- 선형 활성화 함수를 사용
< 다층 퍼셉트론(Multi-Layer perceptron, <MLP) >
-입력층, 은닉층(하나 이상), 출력층으로 구성됨
- 주로 다중분류에 사용됨(이진분류도 가능)
- 단층 퍼셉트론보다 높은 성능을 나타냄
- 여러 층(입력,은닉,출력)으로 이루어져 있다고 해서 "다층" 이라고 한다.
- 은닉층에는 비선형 활성화 함수를 사용함(시그모디드, 렐루, 등등...)
- 발전된 모델들이 현재 사용되는 모델들(계속 나오고있음)
◇ 라이브러리 정의
# 단층 퍼셉트론 모델
from sklearn.linear_model import Perceptron
# 다층 퍼셉트론 모델
from sklearn.neural_network import MLPClassifier
그 외의 라이브러리 정의
# 라이브러리 정의
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 단층 퍼셉트론 모델
from sklearn.linear_model import Perceptron
# 다층 퍼셉트론 모델
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score,confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
◇ 데이터 불러들이기와 전처리
① 데이터 불러들이기
data = pd.read_csv('./data/08_wine.csv')
data.head(1)
② 독립변수와 종속변수로 분리
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
X.shape , y.shape((6497, 3), (6497,))
③ 정규화하기
scaler = StandardScaler()
scaler.fit(X)
X_scaled = scaler.transform(X)
X_scaled.shape(6497, 3)
④ 훈련 : 검증 : 테스트 = 6:2:2 로 분리하기
X_train,X_temp,y_train,y_temp = train_test_split(X_scaled,y,test_size=0.4,random_state=42)
X_val,X_test,y_val,y_test = train_test_split(X_temp,y_temp,test_size=0.5,random_state=42)
print(X_train.shape, X_val.shape , X_test.shape)
print(y_train.shape, y_val.shape , y_test.shape)(3898, 3) (1299, 3) (1300, 3)
(3898,) (1299,) (1300,)
◇ 단층 퍼셉트론
① 단층 퍼셉트론 모델 생성하기
perceptron_model = Perceptron(random_state=42)
perceptron_model
② 하이퍼파라메터 튜닝할 매개변수 범위 설정
param_grid = {
#학습율 = 보폭
"alpha" : [0.0001,0.001,0.01],
# 반복횟수
"max_iter" : [100,500,1000]
}
param_grid{'alpha': [0.0001, 0.001, 0.01], 'max_iter': [100, 500, 1000]}
▶ 반복횟수 max_iter >> epoch와 비슷한 개념
③ 그리드서치cv 객체 생성하기
grid_search = GridSearchCV(perceptron_model, param_grid,cv=3,scoring='accuracy')
grid_search
④ 최적의 하이퍼파라메터 찾기
grid_search.fit(X_train,y_train)
⑤ 최적의 하이퍼파라메터 / 모델 출력
# 최적의 하이퍼파라메터
print(grid_search.best_params_)
# 최적의 모델
best_model=grid_search.best_estimator_
print(best_model){'alpha': 0.0001, 'max_iter': 100}
Perceptron(max_iter=100, random_state=42)
⑥ 최적의 모델로 훈련시키기
best_model.fit(X_train,y_train)
⑦ 훈련 및 검증 정확도 확인하기
score_train = best_model.score(X_train,y_train)
score_val = best_model.score(X_val,y_val)
print(score_train,score_val)0.7637249871729092 0.7474980754426482
⑧ 성능 평가하기
- 정밀도, 재현율, f1-score, 오차행렬도 확인하기
y_pred = best_model.predict(X_test)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
print(precision,recall,f1)
print(cm)0.7307692307692307 1.0 0.8444444444444443
[[ 0 350]
[ 0 950]]
- 오차행렬 시각화
plt.figure(figsize=(8,4))
plt.title("Confusion Matrix")
sns.heatmap(cm,annot = True, fmt = "d", cmap = "Blues", cbar = False,
xticklabels=["0","1"],yticklabels=["0","1"])
plt.show()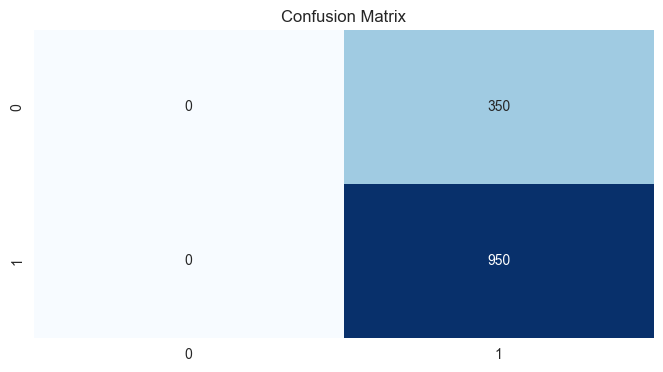
▶ fmt = "d" : 정수
annot = True : 데이터 값 나타내기
xticklabels : x축에 넣을 값
cbar = False : 색상표 제거
>>>> 적합하지 않은 모델로 판단됨
◇ 다층 퍼셉트론
① 다층 퍼셉트론 모델 생성
mlp_model = MLPClassifier(random_state=42)
mlp_model
② 튜닝할 하이퍼파라메터 설정하기
- hidden_layer_sizes : 은닉계층 정의
(10,) : 은닉계층 1개 사용, 출력크기 10개를 의미함
(10,10) : 은닉계층 2개 사용, 각각의 출력크기가 10개라는 의미
(10,11,12) : 은닉계층 3개 사용, 각각의 출력크기는 10,11,12
param_grid = {
"hidden_layer_sizes" :[(10,),(0,),(100)],
"alpha" : [0.0001,0.001,0.01],
"max_iter" : [1000]
}
③ 그리드서치cv 객체 생성하기
grid_search_mlp = GridSearchCV(mlp_model,param_grid,cv=3,scoring='accuracy')
grid_search_mlp
④ 최적의 하이퍼파라메터 찾기
grid_search_mlp.fit(X_train,y_train)
⑤ 최적의 하이퍼파라메터 , 모델 출력
best_model_mlp = grid_search_mlp.best_estimator_
print(grid_search_mlp.best_params_)
print(best_model_mlp){'alpha': 0.01, 'hidden_layer_sizes': 100, 'max_iter': 1000}
MLPClassifier(alpha=0.01, hidden_layer_sizes=100, max_iter=1000,
random_state=42)
⑥ 훈련 및 검증 정확도 확인하기
score_train = (best_model_mlp.score(X_train,y_train))
score_val= best_model_mlp.score(X_val,y_val)
score_train, score_val(0.8755772190867112, 0.8683602771362586)
⑦ 예측하기
y_pred = best_model_mlp.predict(X_test)
y_pred
⑧ 성능 평가하기
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test,y_pred)
f1 = f1_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
print(precision,recall,f1)
print(cm)0.8875255623721882 0.9136842105263158 0.900414937759336
[[240 110]
[ 82 868]]
⑨ 혼동행렬 시각화

▶ 단층 퍼셉트론보다는 성능이 향상된 것을 확인할 수 있다.
'머신러닝&딥러닝' 카테고리의 다른 글
| [딥러닝] 순환신경망 - LSTM , GRU (0) | 2024.01.08 |
|---|---|
| [딥러닝] 순환신경망(RNN) - 심플 순환신경망(Simple RNN) (1) | 2024.01.05 |
| [딥러닝] DNN 분류데이터 사용(실습) (4) | 2024.01.04 |
| [딥러닝] DNN 회귀데이터 사용 (0) | 2024.01.04 |
| [딥러닝] 모델 저장 및 불러들이기 / 성능 향상 / 예측 (2) | 2024.01.04 |