
< 순환신경망(Recurrent Neural Network , RNN) >
- RNN은 텍스트 처리를 위해 고안된 모델(계층)
- 바로 이전의 데이터(텍스트)를 재사용하는 신경망 계층임
< 순환신경망 종류 >
- 심플 순환신경망(Simple RNN)
- 장기기억 순환신경망(LSTM)
- 게이트웨이 반복 순환신경망(GRU)
○ 라이브러리 정의
# 사용 라이브러리
import tensorflow as tf
from tensorflow import keras
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
○ 사용할 데이터 셋
< IMDB : 영화 리뷰 감상평 데이터 >
- 순환신경망에서 대표적으로 사용되는 데이터셋(외국)
- 케라스에서 영어로된 문장을 정수(숫자)로 변환하여 제공하는 데이터셋
- 감상평이 긍정과 부정으로 라벨링되어있음
- 총 50,000개의 샘플로 되어있으며 훈련 및 테스트로 각각 25,000개씩 분리하여 제공됨
from tensorflow.keras.datasets import imdb
① 데이터 읽어들이기
- num_words = 500 : 말뭉치 사전의 개수 500개만 추출하겠다는 의미
- 말뭉치 사전 : 고유한 단어들만 모아둔 것(인덱스 값 가지고 있음)
imdb.load_data(num_words=500)((array([list([1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 458, 2, 66, 2, 4, 173, 36, 256, 5, 25, 100, 43, 2, 112, 50, 2, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 2, 2, 17, 2, ....array([0, 1, 1, ..., 0, 0, 0], dtype=int64)))
▶ 리스트 하나가 문장 , 문장 50000개와 긍정 부정을 0과 1로 표현한 감상평이 있다.
(train_input , train_target),(test_input,test_target) = imdb.load_data(num_words=500)
print(f"{train_input.shape} / {train_target.shape}")
print(f"{test_input.shape} / {test_target.shape}")(25000,) / (25000,)
(25000,) / (25000,)
▶ 총 50000개의 데이터 중 25000개 씩 train과 test로 나뉘어져 있다.
첫번째 train_input 데이터 확인
print(len(train_input[0]), train_input[0])218 [1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 458, 2, 66, 2, 4, 173, 36, 256, 5, 25, 100, 43, 2, 112, 50, 2, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, ....]
▶ 218개의 단어로 이루어진 문장이다.
② 훈련 : 검증 = 8 : 2로 분리하기
from sklearn.model_selection import train_test_split
train_input,val_input,train_target,val_target = train_test_split(train_input,train_target,test_size=0.2,random_state=42)
print(train_input.shape, train_target.shape)
print(val_input.shape, val_target.shape)
print(test_input.shape, test_target.shape)(20000,) (20000,)
(5000,) (5000,)
(25000,) (25000,)
③ 정규화(텍스트 데이터)
- 텍스트 기반의 데이터인 경우 정규화는 스케일링 처리가 아닌
문자열의 길이를 통일시키는 처리를 진행한다
- 훈련 모델은 정해진 행렬의 사이즈를 기준으로 훈련하기 때문
○ 훈련 독립변수의 각 데이터(값)의 길이를 배열(리스트) 형태로 추출하기
lengths = np.array([len(i) for i in train_input])
print(lengths)[259 520 290 ... 300 70 77]
▶ 총 20000개의 값을 가지는 리스트 lengths 생성, numpy 사용 용이하게 하기 위한 np.array로 묶기
○ lengths의 값을 이용해서 전체 평균과 중앙값 추출하기
np.mean(lengths),np.median(lengths)(239.00925, 178.0)
▶ 평균 239 , 중앙값 178 ,중앙값이 평균보다 작음
○ 텍스트 길이 분포 시각화
# 시각화
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rc('font', family='Malgun Gothic')
plt.title("텍스트 길이 분포 확인")
plt.hist(lengths)
plt.xlabel("length(단어 개수)")
plt.ylabel("빈도")
plt.show
▶ 중앙값이 평균보다 작으면 왼쪽에 더 많다. 실제 그래프도 그러하다
단어 개수의 분포를 이용해서 훈련에 사용할 독립변수 각 값들의 길이 기준 정의
전체적으로 왼쪽편에 집중되어있으며 x축 125정도에 많은 빈도를 나타내고 있음
따라서 독립변수 각 값들의 길이를 100으로 통일(정규화)
○ 각 데이터의 길이를 100으로 통일(정규화) 시키기
- pad_sequences() : 텍스트의 길이를 maxlen 개수로 통일시키기
- maxlen보다 작으면 0으로 채우고, 크면 제거함
- 결과값은 2차원 리스트로 반환된다
# 텍스트 길이 정규화 라이브러리
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 훈련 독립변수 각 데이터 100개로 통일시키기
train_seq = pad_sequences(train_input,maxlen=100)
train_seq.shape(20000, 100)
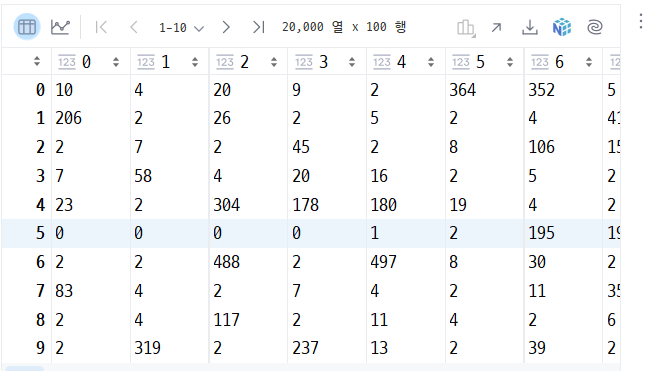
▶ maxlen보다 작은 개수를 가져 앞에서부터 부족한 개수만큼 0으로 채워진 경우를 확인할 수 있다.
maxlen보다 큰 경우에는 앞쪽을 제거한 것을 알 수 있다.
○ 검증데이터도 길이 100으로 통일 시키기
val_seq = pad_sequences(val_input,maxlen= 100)
val_seq.shape(5000, 100)
○ 텍스트 길이 조정 속성(매개변수)
* truncating : 추출 위치(앞 또는 뒤부터)
- pre : 뒤쪽부터 추출하기(기본값)
- post : 앞쪽부터 추출하기
* padding : 채울 위치(앞 또는 뒤부터)
- pre : 앞쪽을 0으로 채우기(기본값)
- post : 뒤쪽을 0으로 채우기
train_seq = pad_sequences(train_input,maxlen= 100,
truncating='pre',
padding='pre')
④ 모델 생성하기 및 계층 추가하기
- input_shape=(100,500) : 100은 특성 개수, 500은 말뭉치 개수
# 모델 생성하기
model = keras.Sequential()
# 입력계층이면서 RNN 계층
model.add(keras.layers.SimpleRNN(8, input_shape=(100,500)))
# 출력계층
model.add(keras.layers.Dense(1, activation='sigmoid'))
< RNN에서 사용할 독립변수 처리 방식 >
- RNN 모델에서는 독립변수의 데이터를 원-핫 인코딩 데이터 또는 임베딩 처리를 통해서
훈련을 시켜야한다.
< 원-핫 인코딩(One-Hot) 인코딩 방식 >
- 각 데이터(값) 중에 1개의 단어당 분석을 위해 500개의 말뭉치와 비교하여야 함
- 이때 비교하기 위해 원-핫 인코딩으로 변환하여 비교하는 방식을 따름
- keras.utils.to_categorical() 함수 사용
- 프로그램을 통해 변환해야함(별도 계층이 존재하지는 않음)
- 각 단어별로 원-핫인코딩 처리가 되기에 데이터가 많아지며, 속도가 느림
- 데이터가 많아지기 때문에 많은 메모리 공간을 차지함
<단어 임베딩(Embedding) 방식 >
- 원-핫인코딩의 느린 속도를 개선하기 위해서 개선된 방식(메모리 활용)
- 많은 공간을 사용하지 않음
- keras.layers.Embedding() 계층을 사용함(프로그램 처리방식이 아님)
◇ 원-핫 인코딩 데이터로 변환하기
train_oh = keras.utils.to_categorical(train_seq)
train_oh.shape(20000, 100, 500)
▶ 20000개의 문장 중 한 문장에 100개의 단어가 들어있으며,
그 단어가 만약 10 이면 500개의 0 또는 1로 이루어진 배열에서
10번째 인덱스만 1이고 나머지는 0인 경우를 의미한다.
검증 데이터도 변환
val_oh = keras.utils.to_categorical(val_seq)
val_oh.shape
⑤ 모델 설정하기
- 순환신경망에서 주로 사용되는 옵티마이저는 RMSProp
- RMSProp : 먼 거리는 조금 반영, 가까운 거리는 많이 반영하는 개념을 적용함
rmsprop = keras.optimizers.RMSprop(learning_rate=0.0001)
model.compile(optimizer = rmsprop,
loss='binary_crossentropy',
metrics=['accuracy'])
⑥ 콜백 함수 정의하기
# 자동 저장 및 종료하는 콜백함수 정의하기
model_path = "./model/best_simpleRNN_model.h5"
checkpoint = keras.callbacks.ModelCheckpoint(
model_path, save_best_only=True
)
earlystop = keras.callbacks.EarlyStopping(
patience = 3 , restore_best_weights=True
)
⑦ 모델 훈련시키기
- batch_size : 훈련 시 데이터를 배치사이즈 만큼 잘라서 종속변수와 검증 진행
- 배치사이즈 만큼 종속변수와 비교 시 틀리게 되면,
다음 배치사이즈에서 오류를 줄여가면서 훈련을 진행하게 된다.
- 배치사이즈의 값을 정의하지 않으면 전체 데이터를 기준으로 종속변수와 비교 및
훈련 반복 시 오류 조정 진행됨
- 배치 사이즈의 값은 정의된 값은 없으며, 보통 32, 64 정도를 주로 사용함
- 튜닝 대상 하이퍼파라메터 변수임
history = model.fit(
train_oh, train_target, epochs = 100, batch_size =64,
validation_data=(val_oh,val_target),
callbacks=[checkpoint,earlystop]
)Epoch 60/100
313/313 [==============================] - 6s 18ms/step - loss: 0.4111 - accuracy: 0.8227 - val_loss: 0.4604 - val_accuracy: 0.7856
▶ 60번째 Epoch 까지 진행됨
⑧ 훈련과 검증에 대한 손실 , 정확도 곡선 비교
○ 손실 곡선
plt.plot(history.epoch, history.history['loss'],color = "blue")
plt.plot(history.epoch, history.history['val_loss'],color = "orange")
plt.title('손실곡선')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(["train_loss" , "val_loss"])
plt.show()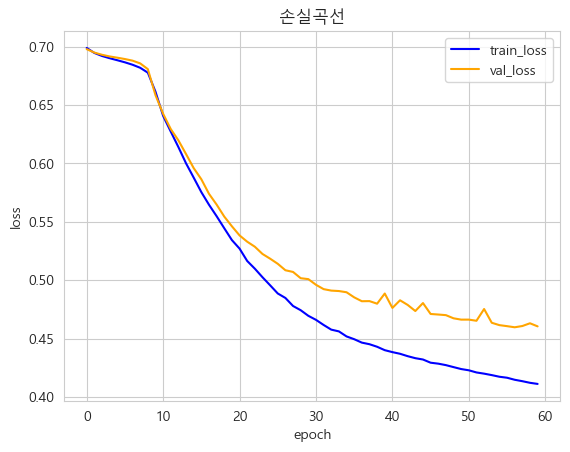
○ 정확도 곡선
plt.plot(history.epoch, history.history['accuracy'],color = "blue")
plt.plot(history.epoch, history.history['val_accuracy'],color = "orange")
plt.title('정확도 곡선')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(["train_accuracy" , "val_accuracy"])
plt.show()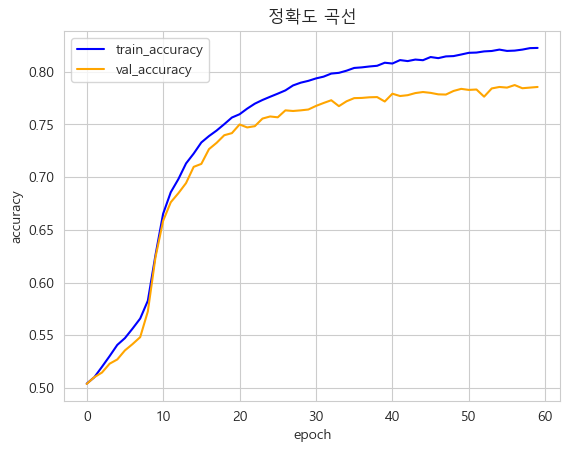
▶ 과적합은 발생하지 않았음
◇ 단어 임베딩 방식
① 모델 생성
model2 = keras.Sequential()
② 계층 생성 및 추가
- 500 : 말뭉치 개수
- 16 : 출력크기(개수)
- input_length : 사용할 특성 개수(input_shape와 동일)
# 입력계층 생성하기(단어임베딩 계층으로 생성)
model2.add(keras.layers.Embedding(500,16,input_length=100))
# Simple RNN 계층 추가
model2.add(keras.layers.SimpleRNN(8))
# 출력계층 추가
model2.add(keras.layers.Dense(1,activation='sigmoid'))model2.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 16) 8000
simple_rnn_1 (SimpleRNN) (None, 8) 200
dense_1 (Dense) (None, 1) 9
=================================================================
Total params: 8,209
Trainable params: 8,209
Non-trainable params: 0
_________________________________________________________________
--- 여기부터는 원-핫 인코딩과 동일 ---
③ 모델 설정 / 훈련
model2.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
history = model2.fit(train_seq,train_target,epochs=100,batch_size=64,validation_data = (val_seq,val_target),
callbacks=[checkpoint,earlystop])Epoch 8/100
313/313 [==============================] - 3s 10ms/step - loss: 0.4183 - accuracy: 0.8149 - val_loss: 0.4762 - val_accuracy: 0.7704
▶원-핫인코딩 때 설정한 콜백함수 그대로 적용
④ 손실, 정확도 곡선 시각화
○ 손실 곡선
plt.plot(history.epoch, history.history['loss'],color = "blue")
plt.plot(history.epoch, history.history['val_loss'],color = "orange")
plt.title('손실곡선(단어임베딩)')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(["train_loss","val_loss"])
plt.show()
○ 정확도 곡선
plt.plot(history.epoch, history.history['accuracy'],color = "blue")
plt.plot(history.epoch, history.history['val_accuracy'],color = "orange")
plt.title('정확도곡선(단어임베딩)')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(["train_accuracy","val_accuracy"])
plt.show()
⑤ 성능평가 하기
# 원-핫데이터 모델로 검증데이터 평가하기
model.evaluate(val_oh,val_target)157/157 [==============================] - 2s 7ms/step - loss: 0.4596 - accuracy: 0.7874 [0.4596419334411621, 0.7874000072479248]
# 단어임베딩 모델로 검증데이터 평가하기
model2.evaluate(val_seq,val_target)157/157 [==============================] - 0s 2ms/step - loss: 0.4691 - accuracy: 0.7838 [0.4691093862056732, 0.7838000059127808]
▶ 미세한 차이로 원-핫인코딩 모델이 검증 정확도가 높게 나왔음
⑥ 테스트 데이터로 원-핫 모델 및 단어 임베딩 모델 평가하기
○ 테스트 데이터 정규화
test_seq = pad_sequences(test_input,maxlen=100)
test_seq.shape(25000, 100)
○ 테스트데이터 원-핫 인코딩
test_oh = keras.utils.to_categorical(test_seq)
test_oh.shape(25000, 100, 500)
○ 원-핫 인코딩 모델 평가
model.evaluate(test_oh,test_target)782/782 [==============================] - 10s 8ms/step - loss: 0.4588 - accuracy: 0.7886 [0.45879143476486206, 0.7885599732398987]
○ 단어 임베딩 모델 평가
model2.evaluate(test_seq,test_target)782/782 [==============================] - 2s 2ms/step - loss: 0.4664 - accuracy: 0.7886 [0.4663991928100586, 0.7885599732398987]
▶ 동일한 정확도가 나왔다. 손실율은 원-핫 인코딩 모델이 조금 더 작다
⑦ 예측 및 정밀도 재현율, f1-score , 혼동행렬도 출력하기
○ 예측하기
- sigmoid 활성화함수를 사용하여 출력계층을 생성했으므로
0.5 이상이면 1, 미만이면 0 을 넣은 예측 생성
y_pred = model.predict(test_oh)
binary_pred = (y_pred > 0.5).astype(int)
binary_pred
○ 정밀도 재현율, f1-score , 혼동행렬도 출력
from sklearn.metrics import confusion_matrix , precision_score, recall_score, f1_score
precision = precision_score(binary_pred, test_target)
recall = recall_score(binary_pred,test_target)
f1 = f1_score(binary_pred,test_target)
cm = confusion_matrix(binary_pred, test_target)
print(precision, recall, f1)
print(cm)0.79 0.7877313337587747 0.7888640357884645
[[9839 2625]
[2661 9875]]
○ 혼동행렬도 시각화
import seaborn as sns
plt.title("원핫인코딩 모델 혼동행렬도")
sns.heatmap(cm, annot=True, fmt="d",cmap= "Blues",cbar=False)
plt.show()
▶ 성능이 엄청나게 좋은 최적의 모델은 아니지만 제대로 예측하지 못한 긍정적/부정적 오류보다
제대로 예측한 경우의 건수가 많은 것으로 보아 어느정도는 분류가 잘되는 모델임을 알 수 있음
'머신러닝&딥러닝' 카테고리의 다른 글
| [딥러닝] RNN응용 규칙기반 챗봇 (0) | 2024.01.08 |
|---|---|
| [딥러닝] 순환신경망 - LSTM , GRU (0) | 2024.01.08 |
| [딥러닝] 퍼셉트론 - 분류데이터 사용 (1) | 2024.01.05 |
| [딥러닝] DNN 분류데이터 사용(실습) (4) | 2024.01.04 |
| [딥러닝] DNN 회귀데이터 사용 (0) | 2024.01.04 |