
이전 내용과 이어집니다.
이전 내용을 보고싶으시다면 클릭
데이터 통합
문화 빅데이터 플랫폼에서 총 106개의 데이터를 다운로드해서 파일명을 travel_interest(숫자) 형태로 바꿔놓았습니다.
단순히 코드 작성시 편리하기 위함이므로 굳이 파일명을 변경할 필요는 없습니다.

저번에 샘플링했던 코드를 하나로 모아 제대로 작동되는지 travel_interest(1).csv 파일을 넣어 확인해보겠습니다.
file_path = './01_data/travel_interest(1).csv'
df = pd.read_csv(file_path)
file_path2 = "./01_data/travel_columns.xlsx"
df_col = pd.read_excel(file_path2,header = 0 , usecols = "B:C")
df_col_new_dict = {}
for i in range(17):
df_col_new_dict[df_col.iloc[i,0]] = df_col.iloc[i,1]
df.rename(columns = df_col_new_dict,inplace = True)
for j in range(6,17):
for i in range(len(df)):
if df.iloc[i,j] == "예전과 비슷하다":
df.iloc[i,j] = 0
elif df.iloc[i,j] == "약간 커졌다":
df.iloc[i,j] = 1
elif df.iloc[i,j] == "많이 커졌다":
df.iloc[i,j] = 2
elif df.iloc[i,j] == "약간 적어졌다":
df.iloc[i,j] = -1
elif df.iloc[i,j] == "많이 적어졌다":
df.iloc[i,j] = -2
df = df.astype({"조사시작일자":"str"})
df["조사시작일자"] = pd.to_datetime(df.loc[:,"조사시작일자"])
df["기준년도"] = df["조사시작일자"].dt.year
df["기준월"] = df["조사시작일자"].dt.month
if df.loc[0,"기준월"] in (10,11,12):
df["분기"] = 4
elif df.loc[0,"기준월"] in (7,8,9):
df["분기"] = 3
elif df.loc[0,"기준월"] in (4,5,6):
df["분기"] = 2
elif df.loc[0,"기준월"] in (1,2,3):
df["분기"] = 1
▶ 분기가 기준월인 1월을 기준으로 1분기로 잘 생성되어있고 각각의 도시별 관심값이 -2~2 의 숫자로 변경되어있는 것을 확인 할 수 있습니다.
df_total = pd.DataFrame()
for i in range(106):
file_path = f'./01_data/travel_interest({i}).csv'
df = pd.read_csv(file_path)
file_path2 = "./01_data/travel_columns.xlsx"
df_col = pd.read_excel(file_path2,header = 0 , usecols = "B:C")
df_col_new_dict = {}
for i in range(17):
df_col_new_dict[df_col.iloc[i,0]] = df_col.iloc[i,1]
df.rename(columns = df_col_new_dict,inplace = True)
for j in range(6,17):
for i in range(len(df)):
if df.iloc[i,j] == "예전과 비슷하다":
df.iloc[i,j] = 0
elif df.iloc[i,j] == "약간 커졌다":
df.iloc[i,j] = 1
elif df.iloc[i,j] == "많이 커졌다":
df.iloc[i,j] = 2
elif df.iloc[i,j] == "약간 적어졌다":
df.iloc[i,j] = -1
elif df.iloc[i,j] == "많이 적어졌다":
df.iloc[i,j] = -2
df = df.astype({"조사시작일자":"str"})
df["조사시작일자"] = pd.to_datetime(df.loc[:,"조사시작일자"])
df["기준년도"] = df["조사시작일자"].dt.year
df["기준월"] = df["조사시작일자"].dt.month
if df.loc[0,"기준월"] in (10,11,12):
df["분기"] = 4
elif df.loc[0,"기준월"] in (7,8,9):
df["분기"] = 3
elif df.loc[0,"기준월"] in (4,5,6):
df["분기"] = 2
elif df.loc[0,"기준월"] in (1,2,3):
df["분기"] = 1
df_total = pd.concat([df_total , df] , axis = 0 , ignore_index = True)데이터 프레임명이 df_total 인 통합 데이터의 데이터프레임을 만들어 이를 for문을 통해서 데이터 가공한 뒤 마지막에
pd.concat을 통해 통합해줬습니다.

총 26534 행의 통합데이터가 생성되었습니다.
이제 통합된 데이터를 하나의 파일로 저장합니다.
아래의 코드를 실행하면 파일로 저장됩니다.
save_path = "./01_data/travel_data_total.csv"
df_total.to_csv(save_path,index = False)
저장한 파일을 데이터프레임 형식으로 부를때는 아래와 같이 데이터를 읽어들이면 됩니다.
file_path = "./01_data/travel_data_total.csv"
df = pd.read_csv(file_path)
데이터 시각화
데이터 시각화를 위한 라이브러리를 먼저 import 해줍니다.
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
plt.rc("font", family = "Malgun Gothic")
plt.rcParams["axes.unicode_minus"] = False한글 폰트 깨짐 방지를 위한 font_manager , 폰트 지정 , 마이너스 기호 표시를 위한 설정까지 해줬습니다.
성별에 따른 각 여행지에 대한 관심도 분석
① 서울특별시 성별과 기준년도에 따른 관심도 분석
우선 df_temp라는 데이터프레임에 사용할 데이터만 넣어두고
df_pivot에 각각의 컬럼을 가지고 테이블을 만들었습니다. 이때 서울특별시 여행관심값의 합계를 사용하여
기준년도와 성별에 따른 관심도 차이를 알아볼 것입니다.
df_temp = pd.DataFrame()
df_temp["성별"] = df_total["성별구분코드"]
df_temp["기준년도"] = df_total["기준년도"]
df_temp["서울특별시여행관심값"] = df_total["서울특별시여행관심값"]
df_pivot = df_temp.pivot_table(index = "성별" ,
columns = "기준년도",
values = "서울특별시여행관심값",
aggfunc = "mean")아래와 같은 테이블이 생성되었습니다. 여성에 비해 남성의 관심값이 확연히 적은 것을 볼 수 있습니다.
또한 기준년도별로 보자면 여성 남성 둘다 2022년에 상승하고 2023년도에 하강한 것을 알 수 있습니다.
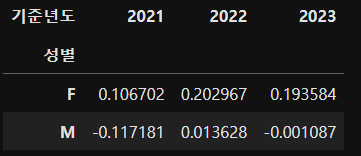
위의 데이터를 그래프로 시각화 했습니다.
plt.figure(figsize=(8,4))
plt.title("서울특별시 남녀 관심도 추이")
sns.barplot( x = "기준년도" , y = "서울특별시여행관심값" , hue = "성별" , data = df_temp )
위의 그래프에서 검은 선으로 나타나는 값이 무엇인지 왜 생기는지 알고자 검색을 해봤습니다.
검은 선 막대기는 신뢰 수준을 나타내는 것으로 Black error bar(ci) 라고 합니다.
Black error bar(ci)
- 기본적으로 나타나게되어있으며 이를 ci = None / errorbar=None 으로 나타나지 않게 할 수 있다.
- 기본값은 95로 이 데이터를 기반으로 유사한 100가지 케이스에서 95개 이상은 해당 범위에서 결과를 얻음을 의미한다.
- ci = 'sd' 를 통해 표준편차를 표현할 수 있다.

위와 동일한 방법으로 광주광역시의 여행관심도를 시각화하였습니다.
fig = plt.figure(figsize=(5,3))
plt.title("전라남도광주광역시 남녀 관심도 추이")
sns.barplot( x = "기준년도" , y="전라남도광주광역시여행관심값", hue = "성별구분코드" , data = df,errorbar=None)
plt.show()
남성의 경우 2021년부터 2023년까지 점점 관심도가 하락하는 추세를 보였고 여성의 경우에는 2022년도에는 상승 2023년에는 하강하는 추세를 보이는 것을 확인할 수 있습니다.
'Project' 카테고리의 다른 글
| [데이터분석 미니프로젝트] - 수질데이터 시각화 / 에너지원별 발전량 데이터 전처리 (0) | 2023.12.08 |
|---|---|
| [데이터분석 미니프로젝트] - 수질 정보 데이터 전처리 (4) | 2023.12.07 |
| [데이터 분석] 국내 여행지역 관심도 분석(1) (5) | 2023.12.01 |
| Vs code 에서 Git hub 연동하기 (4) | 2023.12.01 |
| [Springboot] Springboot MariaDB 연동 (Maven) (10) | 2023.11.29 |