
국가 통계 포털에서 가져온 해수 수질 실태 보고 데이터를 바탕으로 데이터 전처리
https://kosis.kr/index/index.do
KOSIS 국가통계포털
내가 본 통계표 최근 본 통계표 25개가 저장됩니다. 닫기
kosis.kr
연근해 , 항만 , 환경관리해역 환경측정망의 2013-2022 년의 데이터를 사용하였다.
아래 엑셀 표와 같이 제일 위에 년도별로 나누어져있고 행은 지역별(항만/해역명)로 나뉘어 있으며 총 12개의 수질 정보 내역이 나와있는 데이터였는데 이를 년도별로 수질의 변화를 비교하고자 데이터 전처리를 하였다.

pandas 라이브러리 정의 후 파일을 읽어들였다.
df = pd.read_csv("./data/수질현황(2013-2022)/연안수질현황_환경관리해역_환경측정망(2013-2022).csv", encoding="euc-kr")
dfdf_temp = pd.DataFrame()
df_temp = df.iloc[1:,:3]
df_temp앞의 세 컬럼(해역구분, 연안구분명 , 층별구분) 을 df_temp에 넣어줬다.
각각의 년도 데이터에 합칠때 이 세 컬럼을 합친 상태로 행단위로 합칠것이기 때문에 필요하다.
df_temp1 = pd.DataFrame()
df_temp1 = df.iloc[1:,:15]
df_temp1["년도"] = "2013"
df_temp1.columns = ['해역구분(1)', '연안구분명(1)', '층별구분(1)', '수온Temp. (℃)', '염분Sal',
'수소이온농도pH', '용존산소량DO (㎎/ℓ)', '화학적산소요구량COD (㎎/ℓ)',
'클로로필Chl-a (㎍/ℓ)', '총질소TN (㎍/ℓ)', '용존무기인DIP (㎍/ℓ)', '총인TP (㎍/ℓ)',
'규산규소 Si(OH)4 (㎍/ℓ)', '부유물질SPM (㎎/ℓ)', '용존무기질소DIN (㎍/ℓ)','년도']
df_temp1우선 지역명과 2013년의 데이터만 가지는 df_temp1을 생성하였다.
df_tot = df_temp1
for i in range(1,10):
df_temp3 = pd.DataFrame()
df_temp3 = df.iloc[1:,i*12+3:(i+1)*12+3]
df_temp3["년도"] = f"20{i+13}"
df_temp3 = pd.concat([df_temp , df_temp3],axis=1,ignore_index=False)
df_temp3.columns = ['해역구분(1)', '연안구분명(1)', '층별구분(1)', '수온Temp. (℃)', '염분Sal',
'수소이온농도pH', '용존산소량DO (㎎/ℓ)', '화학적산소요구량COD (㎎/ℓ)',
'클로로필Chl-a (㎍/ℓ)', '총질소TN (㎍/ℓ)', '용존무기인DIP (㎍/ℓ)', '총인TP (㎍/ℓ)',
'규산규소 Si(OH)4 (㎍/ℓ)', '부유물질SPM (㎎/ℓ)', '용존무기질소DIN (㎍/ℓ)','년도']
df_tot = pd.concat([df_tot,df_temp3],axis=0,ignore_index=True)
df_tot2014년부터 2022년까지 for문을 통해 concat으로 데이터를 통합하였다.
열단위 합치기로 앞서 저장해둔 df_temp와 데이터를 합친 뒤
년도별 데이터를 행단위로 합쳤다.
df_tot.to_csv("./datapre/수질_환경관리해역.csv",index = False)이를 새로운 csv 파일로 저장한다.

데이터 프레임상으로 1150개 행으로 이루어진 통합데이터를 확인할 수 있다.
수질의 년도별 변화를 확인하여 시간의 흐름에 따라 어떠한 변화가 생겼는지 알아보고자 한다.
우선 해양 수질 평가 기준은 수질 평가 기준으로 계산한 값을 사용하는데 그 계산 방법은 다음과 같다.
수질평가 지수(WQI, Water Quality Index)
- WQI 계산방법 : 10×[저층산소포화도(DO)]+6×[(식물플랑크톤 농도(Chl-a)+
투명도(SD))/2]+4×[(용존무기질소(DIN)+용존무기인(DIP))/2]
여기서 투명도 측정값 데이터의 부재로 나머지 요소들의 측정데이터의 평균을 년도별로 시각화하였다.
우선 전체 데이터에서 필요한 데이터만 추출하여 데이터프레임 df_temp2에 저장하였다.
df_temp2 = pd.concat([df["년도"],df["용존산소량(DO)"]*1000,df["화학적산소요구량(COD)"]*1000,df["클로로필(Chl-a)"],df["용존무기인(DIP)"],df["용존무기질소(DIN)"]],axis=1)
df_temp2 = df_temp2.groupby(["년도"],as_index=False).mean()
df_temp2
단위를 ㎍/ℓ 로 맞추기위해 ㎎/ℓ 단위인 요소의 데이터값에 1000을 곱한 데이터를 넣었다.
fig, ax = plt.subplots(figsize=(8,6))
for i in df_temp2.columns[1:]:
ax.plot(df_temp2["년도"] , df_temp2[i],label = i)
ax.set_title("년도별 수질정보")
ax.legend()
ax.set_xlim(2013,2022)
plt.xlabel("년도",fontweight = "bold")
plt.ylabel("오염물질 농도(㎍/ℓ)",fontweight = "bold")
plt.show()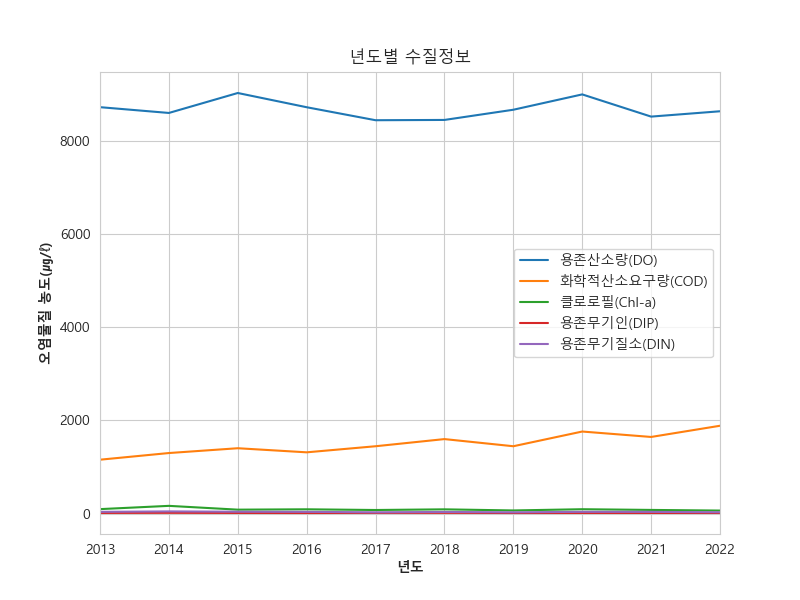
요소마다 값의 크기 차이로 인해 값이 적은 요소는 거의 평이한 모습으로 나타나는것을 확인할 수 있다.
따라서 각 요소마다 따로 그래프를 만드는 방법이 수질의 변화를 보여주기에 적합하다고 판단하여 subplot을 만들었다.
df_temp3 = pd.concat([df["년도"],df["용존산소량(DO)"]*1000,df["화학적산소요구량(COD)"]*1000,df["클로로필(Chl-a)"],df["용존무기인(DIP)"],df["용존무기질소(DIN)"],df["총인(TP)"]],axis=1)
df_temp3 = df_temp3.groupby(["년도"],as_index=False).mean()
df_temp3
위와 동일한 방식으로 필요한 데이터를 df_temp3에 넣었다.
이번에는 총인도 포함하였다.
fig, axs = plt.subplots(2,3,figsize=(15,10))
axs = axs.flatten()
for i , ax in zip(df_temp3.columns[1:], axs):
ax.plot(df_temp3["년도"] , df_temp3[i],label = i,color="green")
ax.set_title(f"년도별 수질정보-{i}")
ax.legend()
ax.set_xlim(2013,2022)
plt.show()
각각의 값의 변화 추이를 선 그래프로 표현하였다.
그러나 점진적으로 증가하거나 점진적으로 감소할 것이라는 나의 예상과는 달리 각각의 요소의 변화가 년도에 따라 감소할때도 증가할때도 있는 것을 알 수 있었다.
수질을 결정하는 평가 요인들은 각각 해당 년도에 기후 , 주변 환경 변화 등에 영향을 받아 불규칙적으로 변화한다는 것을 예상할 수 있다.
'Project' 카테고리의 다른 글
| [데이터분석 미니프로젝트] - 에너지원별 발전량 분석 / 시각화 (2) | 2023.12.09 |
|---|---|
| [데이터분석 미니프로젝트] - 수질데이터 시각화 / 에너지원별 발전량 데이터 전처리 (0) | 2023.12.08 |
| [데이터 분석] 국내 여행지역 관심도 분석(2) (0) | 2023.12.04 |
| [데이터 분석] 국내 여행지역 관심도 분석(1) (5) | 2023.12.01 |
| Vs code 에서 Git hub 연동하기 (4) | 2023.12.01 |